Chapter 7 Constructing Multivariate Portfolios
Chapter Preview. The constrained optimization approach can be used to determine risk retention allocations that are intuitively appealing and have sound and rigorous foundations. However, a difficulty is that this approach can be computationally demanding. Even in today’s world of fast desktop and cloud-based servers, the single evaluation of a risk measure can be computationally challenging. Constrained optimization techniques rely on many such evaluations, making this approach computationally prohibitive for even a small number of risks.
To circumvent these difficulties, this chapter utilizes a simulation strategy outlined in Section 7.1. In many cases, simulation allows analysts to quickly evaluate complex functions. However, there is a cost to this; the simulation approach introduces approximation errors when numerically evaluating functions. This cost is partially mitigated in that the size of the error can be controlled, primarily by increasing the number of replications. Section 7.6 provides additional insights for controlling simulation uncertainty in risk retention problems.
A basic strategy can be improved upon by treating our objective functions, the risk measures, as outputs of a minimization process as outlined in Section 7.2. In addition, Section 7.3 utilizes kernel estimation methods to smooth the simulated objective function. Both of these techniques will speed up the convergence of our algorithms in real time.
Section 7.4 shows how to construct an insurable risk portfolio for an excess of loss contract. Not only is excess of loss a foundational contract, it is our first non-linear retention function applied to many (multivariate) risks. As such, analysis of this contract opens the pathway to an entire host of non-linear retention agreements, some of which are introduced in Section 7.5.
7.1 Simulation Strategy
Simulation, as employed here, is also known as the Monte Carlo technique, cf. Metropolis and Ulam (1949). For the simulation stage, one specifies a large number, \(R\), of replications. Then, for each replicate \(r=1, \ldots, R\):
- Create a realization of dependent multivariate uniform random variates \((V_{1r}, V_{2r}, \ldots, V_{pr})\). For example, one way to do this is via the
Rpackagecopulausing the functionrCopula. - Create a realization of dependent multivariate losses \((X_{1r}, X_{2r}, \ldots, X_{pr})\), denoted by the vector \({\bf X}_{r}\).
- One way to do this is to use the inverse of each distribution function, \(X_{jr} = F_j^{-1}(V_{jr})\), \(j= 1, \ldots, p\).
- For example, if the \(j\)th variate has a Pareto distribution, this can be done via the
Rpackageactuarusing the functionqpareto.
- Create a realization of that portion retained by the risk owner, \(g({\bf X}_{r};\boldsymbol \theta)\) (for a given set of risk retention parameters \(\boldsymbol \theta\)).
Using the entire simulation distribution, one then creates a function to approximate the risk measure, say, \(RM_R({\bf X}; \boldsymbol \theta)\). For example, if the risk measure is the value at risk, then in R one could use the quantile function.
For risk transfer functions, the initial focus is on quota share and excess of loss policies. In addition, also featured is a combination policy, simply to demonstrate the flexibility of the simulation strategy:
- Quota share: \(g_{QS}({\bf X};\boldsymbol \theta)= \sum_{j=1}^p \theta_j X_j\)
- Excess of loss: \(g_{XL}({\bf X};\boldsymbol \theta)= \sum_{j=1}^p (\theta_j \wedge X_j)\)
- Combination policy: \(g_{Combo}({\bf X};\boldsymbol \theta)= \sum_{j \in Set_{QS}} \theta_j X_j + \sum_{j \in Set_{XL}} (\theta_{j} \wedge X_j)\), where \(Set_{QS}, Set_{XL}\) denotes the sets of risks included in the quota share and excess of loss policies.
Using the same approach, one could create a simulated approximation of the risk transfer cost, say, \(RTC_R(\boldsymbol \theta)\). To illustrate, assuming fair risk transfer costs, \[ \begin{array}{ll} RTC_R(\boldsymbol \theta) &= \frac{1}{R} \sum_{r=1}^R \left\{ \sum_{j=1}^p X_{rj} - g({\bf X}_{r};\boldsymbol \theta) \right\} \\ &= \mathrm{E}_R \left\{ \sum_{j=1}^p X_{j} - g({\bf X};\boldsymbol \theta) \right\} , \end{array} \] where \(\mathrm{E}_R(\cdot)\) is the empirical (or simulation) expectation. For some problems we will see that numerically calculating the risk transfer cost is relatively straight-forward and there is no need to introduce a simulation-based approximation.
In addition to a budget restriction (\(RTC_R(\boldsymbol \theta) \le RTC_{max}\)), it will also be common to constrain the risk retention parameters. For example, most problems will require the parameters to be non-negative. In addition, it is common for quota share problems to restrict parameters to be bounded above by one; this prevents the risk owner from transferring more than a realized loss.
To be concrete, define \({\bf 1}_j\) to be a vector of zeros with a one in the \(j\)th position. Then, the requirement \(\theta_j \ge 0\) is equivalent to \(-{\bf 1}_j' \boldsymbol \theta \le 0\). In the same way, the requirement \(\theta_j \le 1\) is equivalent to \({\bf 1}_j' \boldsymbol \theta \le 1\). Because these restrictions are linear in the parameters, we can summarize them as \({\bf P} \boldsymbol \theta \le {\bf p}_0\). As we use \(m\) for the number of constraints, the dimensions of \({\bf P}\) and \({\bf p}_0\) are \((m-1) \times p\) and \((m-1) \times 1\), respectively. (The budget restriction is the \(m\)th constraint.)
With a risk measure, transfer cost function, and parameter restrictions in place, we then solve the simulation version of Display (3.3) given as
\[\begin{equation} \begin{array}{lcc} {\small \text{minimize}_{\boldsymbol \theta}} & ~~~~~RM_R[g({\bf X}; \boldsymbol \theta)] \\ {\small \text{subject to}} & ~~~~~RTC_R(\boldsymbol \theta) \le RTC_{max} \\ & {\bf P} \boldsymbol \theta \le {\bf p}_0 ~~. \end{array} \tag{7.1} \end{equation}\]
In the operations research and management science literature, the combination of simulation and optimization techniques is known as simulation optimization, cf. Fu (2015a).
Example 7.1. Optimal Retention Policies for ANU Risks. To see how this works, let us revisit the ANU Risk Data from Section 6.3.2 with \(p=14\) risks (omitting the property risk). Simulation of ANU risks is realistic and thus a bit complex. The risk parameters and the generation of the random variables will be described beginning in Appendix Section 8.3.4.
For the retention policies, let us consider an excess of loss, quota share, and a combination policy as described above. For the quota share component of the combination policy, I selected three risks, Group Personal Accident, Corporate Travel, and Motor Vehicle; the other risks are on an excess of loss basis. These three risks have relatively high frequency (compared to the other risks) and so would not typically be the subject of a single excess of loss contract; Section 7.5.3 describes alternatives.
For simplicity, fair pricing is used to determine the risk transfer cost and I use \(RTC_{max} = 433\) (in thousands of AUD) for the maximal risk transfer cost budgeted. As will be seen in later examples in this chapter, this is a typical value on a frontier of costs. For the other restrictions, all risk retention parameters are non-negative and quota share parameters are bounded above by one. Thus, for optimizing the excess of loss contract, there are \(m=15\) parameter restrictions (one for the budget plus one for each of 14 parameters), for the quota share there are 29 restrictions (\(=1 + 2\times 14\)), and 18 for the combination policy (\(=1 + 14 + 3\)).
The optimization was coded using the package alabama without taking additional derivatives, as described in Section 4.4.2. Subsequent sections in this chapter will describe methods for improving this optimization procedure although the results show that even this rudimentary approach is successful for this application.
The objective is to minimize the standard deviation of retained risks. This traditional risk measure was chosen for simplicity and more realistic measures will be considered in the following section. Table 7.1 summarizes the optimization results for the three retention functions. The results show that the excess of loss and combination policies achieved a lower standard deviation of retained risks than the quota share policy. Each optimization run was based on minimization over 14 risk retention (decision) parameters although only the first, second, and sixth are displayed in the table (\(\theta_1\), \(\theta_2\), and \(\theta_6\), for General and Property Liability, Cyber, and Group Personal Accident, respectively). For the combination policy, I used the optimal values from the corresponding excess of loss and quota share policies as starting values. It turned out that these were very close to the resulting optimum.
With specific values of the risk retention parameters, one can compute any risk measure desirable, such as \(VaR\) and \(ES\). Table 7.1 also shows the value at risk and expected shortfall at the optimal risk retention parameters, computed using level of confidence \(\alpha = 0.80\). These values will serve as comparisons with subsequent examples.
R Code for Example 7.1
| \(RTC\) | \(VaR\) | \(ES\) | Std Dev | \(\theta_1^*\) | \(\theta_2^*\) | \(\theta_6^*\) | |
|---|---|---|---|---|---|---|---|
| Excess of Loss | 433 | 1443.9 | 2492.1 | 1024.7 | 1419.422 | 1005.995 | 59.132 |
| Quota Share | 433 | 1269.1 | 2674.7 | 1312.8 | 0.119 | 0.946 | 1.000 |
| Combination | 433 | 1443.9 | 2492.1 | 1024.7 | 1419.422 | 1005.995 | 1.000 |
| Note: Objective function is standard deviation of retained risks. |
7.2 Risk Measures as Minimizers
Although the representation in Display (7.1) is intuitively appealing, the evaluation of associated risk measures can be computationally challenging. As a tool to assist with this computational challenge, this section demonstrates how to write two risk measures, the \(VaR\) and the \(ES\), as solutions of constrained optimization problems.
7.2.1 Value at Risk
First recall from equation (2.1) that we can write the value at risk as a quantile, \(VaR[g(X;\boldsymbol \theta)] = F_{g(X;\boldsymbol \theta)}^{-1}(\alpha)\), with confidence level \(\alpha\). Moreover, as suggested in Section 5.4.2, we can also express the value at risk as the solution of a constrained minimization problem, \[\begin{equation} \boxed{ \begin{array}{lc} {\small \text{minimize}_{z_0} } & ~~~~~z_0 \\ {\small \text{subject to}} & ~~~~~F_{g(X;\boldsymbol \theta)}(z_0) \ge \alpha. \end{array} } \tag{7.2} \end{equation}\]
\(Under~the~Hood.\) Confirm the \(VaR\) as a Solution of Display (7.2)
The value at risk \(F_{g(X;\boldsymbol \theta)}^{-1}(\alpha)\) provides a solution to the problem in Display (7.2) for fixed values of \(\boldsymbol \theta\). We can now take the minimum of all such solutions over different values of \(\boldsymbol \theta\) while restricting consideration to a feasible set. Thus, subject to mild continuity requirements, our problem of interest \[ \boxed{ \begin{array}{lc} {\small \text{minimize}_{\boldsymbol \theta}} & ~~~~~VaR_{\alpha}[g(X;\boldsymbol \theta)] \\ {\small \text{subject to}} & ~~~~~RTC(\boldsymbol \theta) \le RTC_{max} \end{array} } \] is equivalent to \[\begin{equation} \boxed{ \begin{array}{lc} {\small \text{minimize}_{z_0,\boldsymbol \theta}} & ~~~~~z_0 \\ {\small \text{subject to}} & ~~~~~F_{g(X;\boldsymbol \theta)}(z_0) \ge \alpha \\ & ~~~~~RTC(\boldsymbol \theta) \le RTC_{max} . \end{array} } \tag{7.3} \end{equation}\] Using this approach, one no longer has to compute the quantile directly, only the distribution function of retained risks. This formulation is known as chance-constrained programming, cf. Henrion (2024).
Example 7.2. Bivariate Excess of Loss Using \(VaR\) Optimization. We return to Example 5.8 that considers two risks that depend on one another through a Gaussian copula with parameter \(\rho = 0.5\). The first risk is \(X_1\), with a gamma distribution having shape parameter 2 and scale parameter 2,000, and the second is \(X_2\), with a Pareto distribution having shape parameter 3 and scale parameter 2,000. A level of confidence \(\alpha =\) 0.85 is used. For comparison purposes, recall that for this example we were able to use deterministic methods to compute the optimal upper limits \(u_1 =\) 3,113 and \(u_2 =\) 364,924 with value at risk \(VaR =\) 4,757 and expected shortfall \(ES =\) 6,673.
From this joint distribution, \(R = 50,000\) losses were simulated. The appended R code shows two approaches. The first follows Display (7.1), using the quantile as the risk measure (as before, we use \(RTC_{max} = 1,500\) for the budget constraint). This does well but, as we learned in Chapter 5, it is important to start near the optimal values. The second approach is based on Display (7.3), using a “usual” simulated distribution function. This approach did not fare well in this experiment; an improvement is described in the next section.
R Code to Simulate Data for Example 7.2
R Code for the Basic Simulation VaR Optimization in Example 7.2
R Code to Optimize Using the Distribution Function Approach in Example 7.2
7.2.2 Expected Shortfall
As with the value at risk in Display (7.2), we can also express the expected shortfall \(ES\) as the solution of a minimization problem. To this end, consider again a generic random variable \(Y\) having distribution function \(F\) with a unique \(\alpha\) quantile, \(F^{-1}(\alpha)\). Recall in Section 5.3.2 we defined the function \[ ES1_F(z_0) = z_0 + \frac{1}{1-\alpha} \mathrm{E}[(Y-z_0)_+] . \] With this, it is easy to check that the solution of the unconstrained minimization problem \[ \boxed{ \begin{array}{lc} {\small \text{minimize}_{z_0}} & ~~~~~ES1_F(z_0) \end{array} } \] is \(F^{-1}(\alpha)\). Moreover, the minimum value is \(ES1_F[F^{-1}(\alpha)] = ES\).
\(Under~the~Hood.\) Show the Solution of the \(ES\) Minimization Problem
To extend this to the risk retention problem, we first use the retained risk variable \(g({\bf X};\boldsymbol \theta)\) in place of \(Y\). Next, we take the minimum of all such solutions over different values of \(\boldsymbol \theta\) while restricting consideration to a feasible set. Here is a summary of the simulation version of the expected shortfall retention problem: \[\begin{equation} \boxed{ \begin{array}{lc} {\small \text{minimize}_{z_0 ,\boldsymbol \theta}} & z_0 + \frac{1}{(1-\alpha)} \mathrm{E}_R\{ [g({\bf X};\boldsymbol \theta) - z_0]_+\} \\ {\small \text{subject to}} & ~~~~~RTC_R(\boldsymbol \theta) \le RTC_{max} \\ & {\bf P} \boldsymbol \theta \le {\bf p}_0 ~~. \end{array} } \tag{7.4} \end{equation}\]
Example 7.3. Bivariate Excess of Loss Using \(ES\) Optimization. This is a continuation of Example 7.2. As before, we use \(R = 50,000\) simulated bivariate risks. The associated R code shows two approaches. The first follows Display (7.1), using the expected shortfall as the risk measure. The second is based on Display (7.4). For comparison purposes, recall from the discussion in Example 7.2 that we were able to use deterministic methods to compute the optimal upper limits \(u_1 =\) 4,257 and \(u_2 =\) 781 with value at risk \(VaR =\) 5,038 and expected shortfall \(ES =\) 5,038.
Both approaches work well for this demonstration although the first did better than the second. This may be that the first approach, from Display (7.1) with the expected shortfall as the risk measure, optimizes over two parameters in contrast to the three parameters (\(x, u_1, u_2\)) in the second. Further, through experimentation, we learned that starting values are more important than the number of simulations.
R Code to Optimize Using ES
R Code to Optimize Using Display (7.4)
7.3 Kernel Smoothing
The minimization procedure in Display (7.1) can be improved by smoothing the simulated estimates of the distribution using well established methods from statistics.
7.3.1 Nonparametric Smooth Estimation
To provide a quick overview of the kernel smoothing idea, let us think of a simple situation where we have a set of \(R\) i.i.d. replications, \(\{Y_1, \ldots, Y_R\}\), of a single random quantity. The usual (nonparametric) estimator of the distribution function, \(\Pr(Y \le y) = F_Y(y)\), is \[ \hat{F}_Y(y) = \frac{1}{R} \sum_{r=1}^R I(Y_r \le y) = \mathrm{E}_R \{ I(Y \le y)\} , \] where you will recall that \(\mathrm{E}_R\) is the empirical (or simulation) expectation. It is the “usual” estimator because it has several nice properties, including being unbiased. To estimate the corresponding probability density function, \(f_Y(y)\), it is common to use a kernel density estimator of the form \[ f_{Rk}(y) = \frac{1}{R~b} \sum_{r=1}^R k\left(\frac{y - Y_r}{b}\right) , \] where \(k(\cdot)\) is a probability density function centered about 0 and \(b\) is a constant known as the bandwidth parameter. Motivated by this estimator, one can define an alternative distribution function estimator of the form \[ \begin{array}{ll} F_{Rk}(y) &= \int^y f_{Rk}(x) dx = \frac{1}{R} \sum_{r=1}^R K\left(\frac{y - Y_r}{b}\right) \\ &= \mathrm{E}_R \left\{ K\left(\frac{y - Y_r}{b}\right)\right\} , \end{array} \] where \(K(y) = \int^y k(z) dz\) is the distribution function corresponding to density \(k(\cdot)\). When compared to the usual estimator, it is known that the estimator \(F_{Rk}\) is slightly biased but has a lower variance. So, for routine applications, there is a trade-off in terms of bias and variance and certainly the estimator \(\hat{F}_Y(\cdot)\) is more commonly applied.
We can use these smoothed simulated distributions to estimate other quantities. For example, for a generic function \(h(\cdot)\), we can approximate \(\mathrm{E}[h(Y)]\) using \[\begin{equation} \begin{array}{ll} \mathrm{E}_{Rk}[h(Y)] &= \int h(y) f_{Rk}(y) dy \\ &={\LARGE \int} \left\{\frac{1}{R} \sum_{r=1}^R h[Y_r + bz] \right\} ~k(z) dz \\ &={\LARGE \int} \mathrm{E}_{R} \left\{ h[Y_r + bz] \right\} ~k(z) dz .\\ \end{array} \tag{7.5} \end{equation}\] Note that the evaluation of \(\mathrm{E}_{Rk}[h(Y)]\) in equation (7.5) requires only a single one dimensional integration, a tractable task.
For our applications, we routinely use the retained risk \(Y = g({\bf X}; \boldsymbol \theta)\) - our interest is in the distribution function as we vary (and try to optimize over) the parameters in \(\boldsymbol \theta\). A drawback of the usual estimator is that \(\hat{F}_Y\) employs indicator (or “check”) functions of the form \(I[g({\bf X}_r; \boldsymbol \theta) \le y]\) that are discontinuous in the parameters (even if the function \(g\) is smooth). In contrast, we can use a smooth kernel function \(K(\cdot)\) such as the cumulative normal probability function in the alternative estimator \(F_{Rk}\) that does not share this drawback. You can learn more about the mathematics underpinning the kernel smoothing in Appendix Section 10.5.3.
Example 7.5. Bivariate Excess of Loss Using \(VaR\) Optimization and Smoothing. This is a continuation of Example 7.2, using the second approach based on the smooth simulated distribution function. Specifically, we consider
\[
\boxed{
\begin{array}{lc}
{\small \text{minimize}_{z_0,\boldsymbol \theta}} & ~~~~~z_0 \\
{\small \text{subject to}} & ~~~~~F_{Rk}(x) \ge \alpha \\
& ~~~~~RTC(\boldsymbol \theta) \le RTC_{max} .
\end{array}
}
\]
In the appended sample code, we use the kcde function from the R library ks. An advantage of using this package is that it automatically determines an appropriate bandwidth \(b\). This approach fares better than the approach based on the usual estimator investigated previously. However, the value at risk is still not an easy problem due to the need to start near the optimal values, as noted in Chapter 5.
R Code to Optimize Using the Smoothed Distribution Function Approach in Example 7.5
7.3.2 Expected Shortfall and its Derivatives
Using equation (7.5), we may evaluate the function needed for expected shortfall minimization as \[\begin{equation} \begin{array}{ll} ES1_{Rk}(z_0, \boldsymbol \theta) &=z_0 + \frac{1}{1-\alpha} {\LARGE \int} \mathrm{E}_{R} \left\{ [g({\bf X}; \boldsymbol \theta) + bz -z_0]_+ \right\} ~k(z) dz .\\ \end{array} \tag{7.6} \end{equation}\] Expected Shortfall Derivatives. This function is smooth in the decision variables \((z_0, \boldsymbol \theta)\), a property that we can use to speed up the convergence of the algorithm. Recall our Section 4.4 discussion on using derivatives to speed convergence.
Specifically, we can take partial derivatives of \(ES1_{Rk}\) with respect to the decision variables, to get
\[\begin{equation}
\partial_{z_0}~ES1_{Rk}(z_0, \boldsymbol \theta)
=1 - \frac{1}{1-\alpha}\mathrm{E}_{R} \left\{1-K\left(\frac{z_0-g({\bf X}; \boldsymbol \theta)}{b}\right) \right\}
\tag{7.7}
\end{equation}\]
and
\[\begin{equation}
\partial_{\boldsymbol \theta}~ES1_{Rk}(z_0, \boldsymbol \theta)
=\frac{1}{1-\alpha}\mathrm{E}_{R} \left\{\left[1-K\left(\frac{z_0-g({\bf X}; \boldsymbol \theta)}{b}\right)\right] \partial_{\boldsymbol \theta} g({\bf X}; \boldsymbol \theta) \right\} .\\
\tag{7.8}
\end{equation}\]
Excess of Loss Special Case. To provide intuition, we consider the special case of (multivariate) excess of loss. Here, the set of risk retention parameters is \(\boldsymbol \theta = (u_1, \ldots, u_p)'\). In addition, the risk retention function is \(g({\bf X}; \boldsymbol \theta) = X_1 \wedge u_1 + \cdots + X_p \wedge u_p = S({\bf u})\). For the first parameter,
\[
\begin{array}{ll}
\partial_{\theta_1} ~g({\bf X}; \boldsymbol \theta) &= \partial_{u_1} \left( X_1 \wedge u_1 + \cdots + X_p \wedge u_p\right) \\
&= \partial_{u_1} \left( X_1 \wedge u_1 \right) = I(X_1 > u_1) .
\end{array}
\]
Replicating this for other parameters and organizing the results as a vector yields
\[
\begin{array}{ll}
\partial_{\boldsymbol \theta} ~g({\bf X}; \boldsymbol \theta) &=
\left(\begin{array}{c}I(X_{1} > u_1) \\ \vdots \\ I(X_{p} > u_p) \end{array}\right) .
\end{array}
\]
Exercise 7.6 provides guidance on verifying these results. As suggested in Section 4.4.3, the following sections use these partial derivatives extensively as part of the minimization process.
7.4 Constructing a Portfolio Frontier
When we focused on the quota share problem in Section 7.2.3, due to the linearity of quota sharing, the optimization problem in Display (7.4) was convex and so could be solved very efficiently. However, other risk retention problems are nonlinear (such as an upper limit) and so we utilize more general constrained optimization solvers. Although these general solvers can be applied to a broader set of problems, they have limitations: they are generally less computationally efficient (slower), provide only local optimization, and they rely on starting values to begin their recursive procedures.
This section shows how to handle nonlinear contracts by focusing on excess of loss. Specifically, we now consider \(p\) risks \(X_1, \ldots, X_p\) with upper limits \(\mathbf{u} = (u_1, \ldots, u_p)\) so that the retained risk is \[ S(\mathbf{u}) = X_1 \wedge u_1 + \cdots + X_p \wedge u_p . \] The simulation version of the expected shortfall (multivariate) excess of loss retention problem is: \[\begin{equation} \boxed{ \begin{array}{lc} {\small \text{minimize}_{z_0, \mathbf{u}}} & ES1_{Rk}(z_0,\mathbf{u}) = z_0+ \mathrm{E}_{Rk} \{[S(\mathbf{u})-z_0]_+ \} \\ {\small \text{subject to}} & RTC_R(\mathbf{u}) \le RTC_{max} \\ & u_1 \ge 0, \ldots, u_p \ge 0 . \end{array} } \tag{7.9} \end{equation}\] Assuming fair risk transfer costs, we may write \(RTC_R(\mathbf{u})\) \(= RC_{R1}(u_1)\) \(+ \cdots +RC_{Rp}(u_p)\), where \(RC_{Rj}(u)\) \(= \mathrm{E}_R \left\{(X_{j} - u)_+ \right\}\).
Example 7.6. Constructing a Portfolio Frontier for ANU Risks. To see how this works, we return to Example 7.4 on the ANU Risk Data with \(p=14\) risks except now we consider excess of loss, not quota sharing. As before, use \(\alpha =0.80\) for the level of confidence. (Chapter 8 will investigate the effects of varying \(\alpha\).) As in Example 7.1, starting values are determined using the \(\alpha\) quantile of each risk. Later, in Appendix Section 7.7.3, I show how to compute starting values quickly by using the variance as an approximation to the risk measure of interest, the expected shortfall.
The optimization of Display (7.9) uses the R package alabama and the results are summarized in Table 7.3. From this table, first note that the realized value of the risk transfer cost \(RTC\) at the optimal equals the budgeted amount, \(RTC_{max}=433\). Thus, the constraint is binding which, for our applications, is often a good signal that the algorithm has converged.
In addition to the optimal upper limits \(u^*\), the table also provides corresponding proportions. So, for example, for the first risk the optimal upper limit is \(1,116.1\) (in thousands of AUD). With the simulated distribution having \(R = 100,000\) replicates, this corresponds to the \(92^{nd}\) percentile. Further, note that risks \(5, 6, 7, 9, \dots, 14\) are at the \(100^{th}\) percentile. For risk managers, we interpret this to mean that, given a budget of \(433\) (thousands), the algorithm essentially recommends self-insuring these risks (taking \(u= \infty\)) and using the budget to provide protection for the other risks.
| Param | Opt Value | Param | Opt Value | Opt Prop | Param | Opt Value | Opt Prop |
|---|---|---|---|---|---|---|---|
| RTC | 433 | \(u_{1}\) | 1116.1 | 0.92 | \(u_{8}\) | 1109.3 | 0.967 |
| \(VaR\) | 1529.3 | \(u_{2}\) | 1113.8 | 0.969 | \(u_{9}\) | 1584.4 | 1 |
| \(ES\) | 2476.9 | \(u_{3}\) | 1114.4 | 0.967 | \(u_{10}\) | 1132.5 | 1 |
| StdDev | 1031.5 | \(u_{4}\) | 1119.7 | 0.975 | \(u_{11}\) | 694.6 | 1 |
| \(u_{5}\) | 784.3 | 1 | \(u_{12}\) | 885.2 | 1 | ||
| \(u_{6}\) | 150.8 | 1 | \(u_{13}\) | 642.4 | 1 | ||
| \(u_{7}\) | 309.9 | 1 | \(u_{14}\) | 787.8 | 1 |
R Code Excess of Loss for ANU Risks
7.4.1 A Frontier of Trade-offs
Range of \(RTC_{max}\). Even for risk managers that have a good sense of the budget that they have available for risk protection, there is still considerable interest in understanding alternatives over a range of budget possibilities. At one end, a value of \(RTC_{max} = 0\) corresponds to no risk transfer, meaning that \(u_j = \infty\) for all \(j\) for the excess of loss contract. At the other end of the spectrum, we can develop intuition by assuming fair costing and expectations for risk transfers. This means that \(\mathrm{E}(X_1 + \cdots + X_p)\) is the cost of full insurance or full transfer; for excess of loss, this yields \(u_j = 0\) for all \(j\).
To illustrate, for the ANU Example 7.6, from the simulated distribution, it is easy to calculate the cost of full transfer as 1,443.37. For a range of maximal risk transfer costs, I start with 95% of the full transfer cost and then proceed in deciles down to the 5% level for a total of 11 points. The levels of 100% and 0% are omitted because theory tells us values of risk retention levels at those points. In your own work, you may well choose different ranges of the maximal risk transfer cost but these choices seem sensible for the purposes of this book.
Starting values. Working with this range of maximal risk transfer costs helps immensely with the issue of starting values for the algorithm. This is because when starting with a very high level of \(RTC_{max}\), close to full risk transfer cost, the upper limits will be close to zero (they are zero when \(RTC_{max}\) is at 100% of expectations). Thus, I use some small values of the upper limits as starting values for the algorithm. Proceeding to the next level of \(RTC_{max}\) (say, moving from the 95% to the 85% level), I can use optimal values from the prior level as starting values for the current level, and so on.
Frontier. Table 7.4 summarizes the results of 11 different optimization problems, one for each value of \(RTC_{max}\). Not surprisingly, it shows that as the budget, \(RTC_{max}\), decreases, the uncertainty of retained risk, measured by the \(ES\), increases. As noted earlier, although the optimization is done with respect to the \(ES\) measure, once the optimal upper limits are obtained, it is straightforward to also determine other risk measures. Hence, in Table 7.4 one can provide the \(VaR\) and the standard deviation, \(StdDev\), as alternative risk summary measures. Table 7.4 also shows the actual risk transfer cost, \(RTC\), that in most cases equals the maximum and so the constraint is binding. The exceptions are in the cases where the value of \(RTC_{max}\) is large (the first three rows). Here, optimal upper limits are near the boundary of zero; it is more difficult to achieve convergence in these problems via simulation.
From Table 7.4, we see that the summary measures, \(VaR\), \(ES\), and the standard deviation (\(Std~Dev\)), all increase as the maximal risk transfer cost \(RTC_{max}\) decreases, as anticipated. Further, this is also true of most of the retention parameters \(u_j\). In particular, the table indicates when individual upper limits \(u_j\) are equal or close to zero, the case of no retention or full insurance. This case is of particular interest to risk managers.
| \(RTC_{max}\) | \(RTC\) | \(VaR\) | \(ES\) | Std Dev | \(u_1\) | \(u_2\) | \(u_3\) |
|---|---|---|---|---|---|---|---|
| 1371.2 | 1370.1 | 75.3 | 79.0 | 3.6 | 0.0 | 0.0 | 0.0 |
| 1299.0 | 1293.1 | 151.4 | 153.6 | 2.0 | 1.1 | 0.0 | 0.0 |
| 1154.7 | 1145.1 | 307.1 | 309.6 | 9.6 | 0.0 | 0.0 | 0.0 |
| 1010.4 | 1010.4 | 457.2 | 471.8 | 32.2 | 4.6 | 3.0 | 3.0 |
| 866.0 | 866.0 | 661.4 | 874.7 | 205.9 | 102.6 | 98.6 | 97.1 |
| 721.7 | 721.7 | 896.0 | 1350.5 | 435.5 | 299.7 | 284.9 | 277.2 |
| 577.3 | 577.3 | 1133.4 | 1869.7 | 707.7 | 597.3 | 587.5 | 583.0 |
| 433.0 | 433.0 | 1529.4 | 2476.9 | 1031.4 | 1116.2 | 1114.3 | 1114.4 |
| 288.7 | 288.7 | 1573.2 | 3197.1 | 1416.8 | 2604.1 | 1711.5 | 1749.5 |
| 144.3 | 144.3 | 1573.2 | 3918.8 | 1929.9 | 5890.8 | 2648.8 | 2730.7 |
| 72.2 | 72.2 | 1573.2 | 4279.7 | 2279.5 | 9773.0 | 3437.9 | 3603.5 |
R Code for Expected Shortfall Optimization
R Code Excess of Loss Frontier for ANU Risks
Visualizing the Frontier
Figure 7.1 shows the optimal value of the uncertainty measure versus the risk transfer cost. For each panel, one clearly sees the negative relationship between uncertainty and transfer costs. For the middle panel, these are the optimal values of the expected shortfall. Thus, you can interpret this as an optimal “frontier” - given a risk transfer cost, this is the best (smallest) value of uncertainty that can be achieved. Uncertainty frontiers are familiar constructs to risk managers in an asset allocation context and so this interpretation is appealing.
Because we are minimizing expected shortfall, the left and right panels of Figure 7.1 are not technically “frontiers.” However, as with the middle panel, they demonstrate the trade-off between costs of transferring risks and the uncertainty of retained risks. Some risk managers are comfortable with the value at risk as a measure of uncertainty, whereas others prefer the more traditional standard deviation. Depending on the intended audience, it can be valuable to show that one reaches qualitatively similar conclusions regardless of the risk measure utilized. Section 8.2.3 will revisit the topic of the choice of the risk measure.
Alternative Frontiers. Naturally, analysts are not constrained to portraying measures of uncertainty over a range of risk transfer costs. Alternatively, or in addition, one could display measures of uncertainty versus almost any model parameter or summary measure, depending on the point of emphasis. As illustrations, Chapter 8 will show alternative frontiers that vary by the confidence level \(\alpha\) and the range value at risk parameter \(\beta\). Chapter 9 will show alternatives by levels of dependence. The convention adopted in this book, utilizing risk transfer costs, is motivated by analogies to the Markowitz investment portfolio optimization and so is likely to be familiar to insurance risk managers.
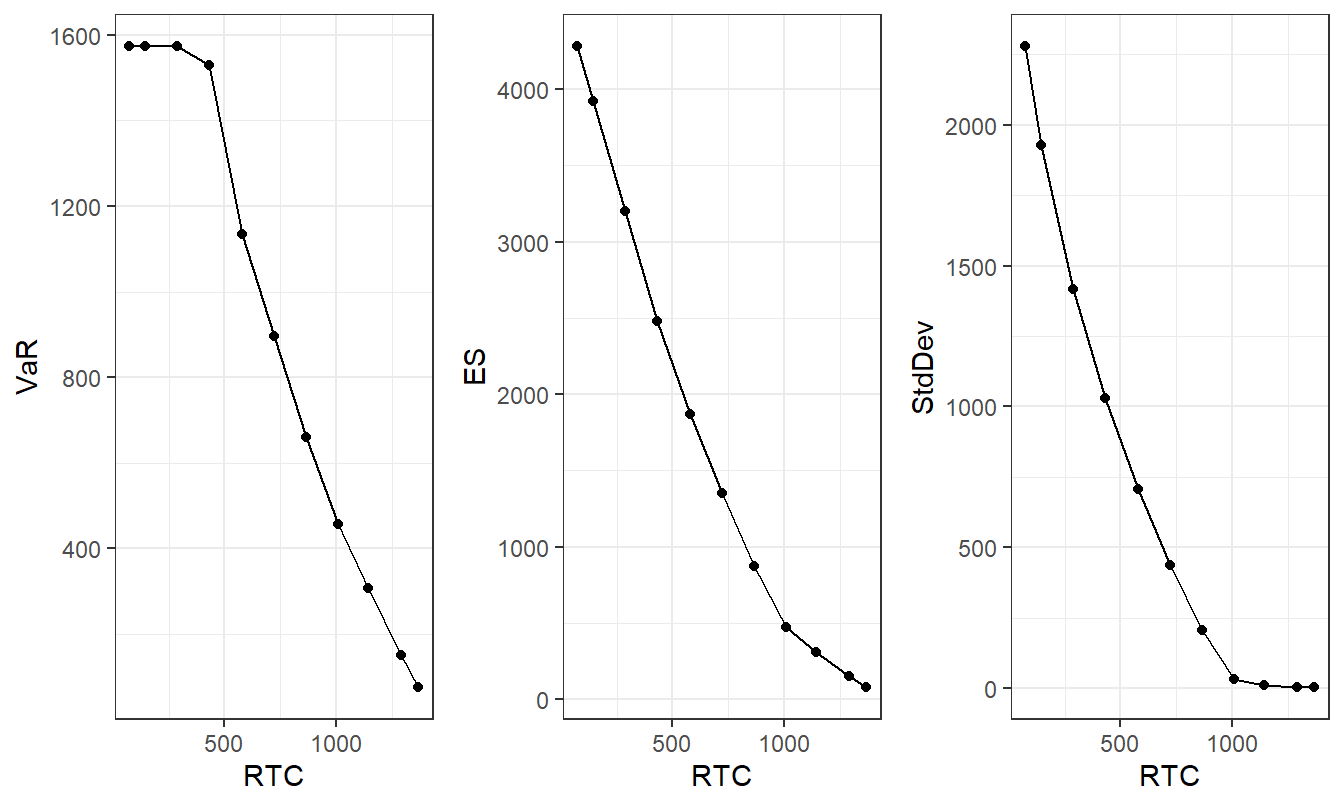
Figure 7.1: ANU Excess of Loss Optimization Results - ES Criterion
Risk Retention Coefficients
It can be difficult to interpret the practical implications of an uncertainty measure, even a standard deviation. In contrast, upper limits are parameters that appear in contracts and so are familiar to risk managers. Figure 7.2 shows how each upper limit changes according to the level of the risk transfer cost. For example, from the upper right panel of Figure 7.2 and the corresponding \(u_3\) column in Table 7.4, we see that the upper limit for the crime coverage decreases slowly as the risk transfer increases. Even when \(RTC = 868\) (which is about 60% of the full transfer amount 1,443.37), the optimal upper limit is only 97.1, suggesting that most of this risk should be transferred (e.g., insured) when a moderate transfer budget is available.
In Figure 7.2, the blue dashed line represents the 99th percentile of the risk displayed in each panel. When the recommended upper limit exceeds that benchmark, we typically interpret this to mean that all of this risk is being retained, corresponding to \(u_j = \infty\). At this level, when a finite risk retention level is used, it is typically not motivated by empirical modeling such as the framework we are pursuing but rather considerations external to the modeling.
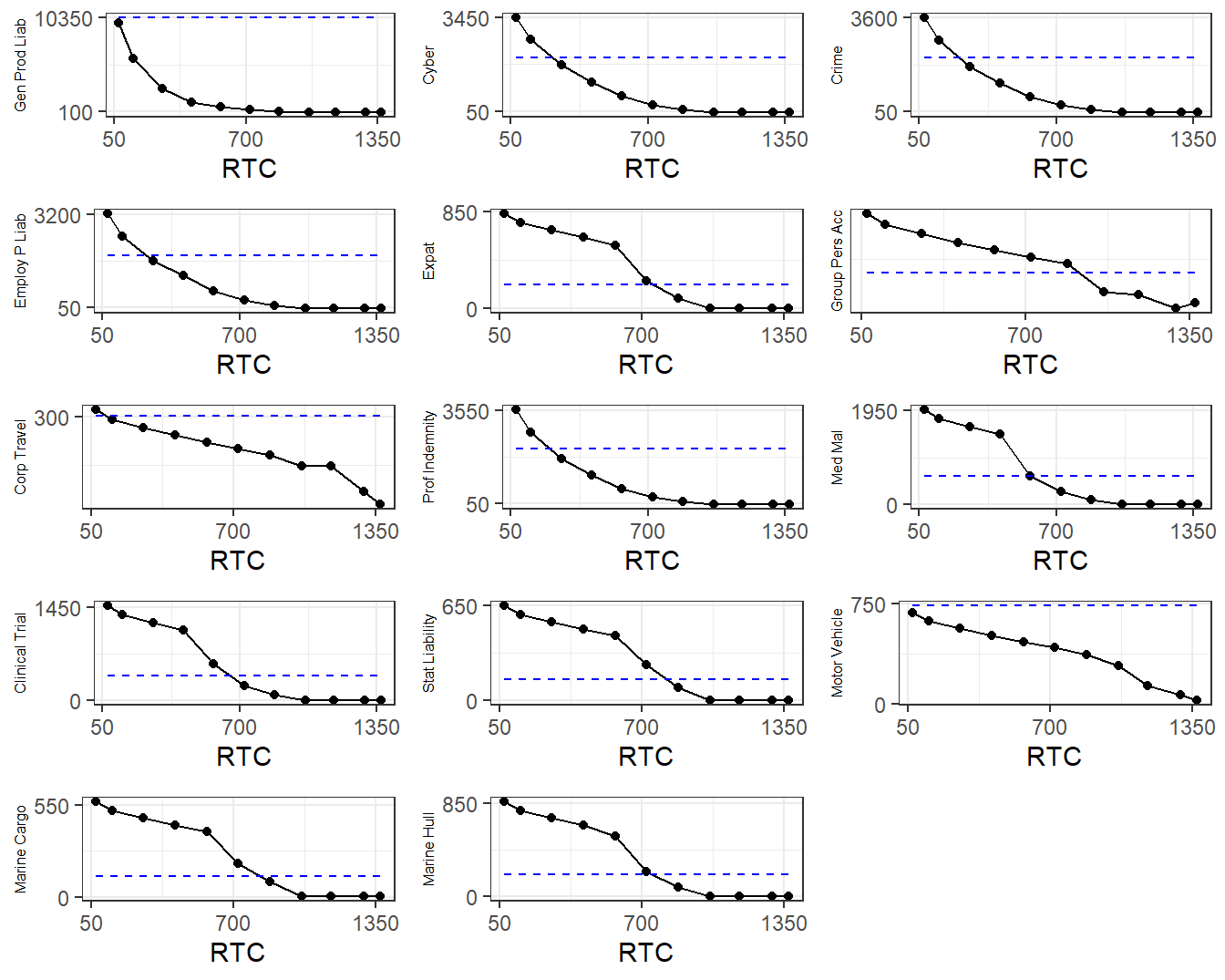
Figure 7.2: ANU Optimal Upper Limits versus Risk Transfer Costs, by Risk Type
7.4.2 Comparing Different Objective Functions
We learned in Section 7.2.3 that minimizing the expected shortfall objective function is equivalent to minimizing the standard deviation for the quota share problem, at least for elliptical risks. How different are the optimal parameter estimates for the excess of loss problem?
To show the similarity among the results, Figure 7.3 compares values of \(StdDev\), \(ES\), and two of the retention parameters, \(u_1\) and \(u_{10}\), for the ANU data. Here, the optimization is done twice, first by minimizing the variance/standard deviation function in Section 7.1 and second by minimizing the expected shortfall in Section 7.4.1. In Figure 7.3, each plotting point represents a different level of \(RTC_{max}\).
The top row of Figure 7.3 compares the two risk measures obtained using the different objective functions. It shows that the values of the risk measures are largely comparable. In addition, the bottom row compares values of two retention parameters, the first and the tenth, obtained from the two minimization criteria. Values of the first parameter obtained by different objective functions are largely equivalent whereas those from the tenth parameter displays markedly different values for some levels of \(RTC_{max}\).
R Code for Section 7.4.2
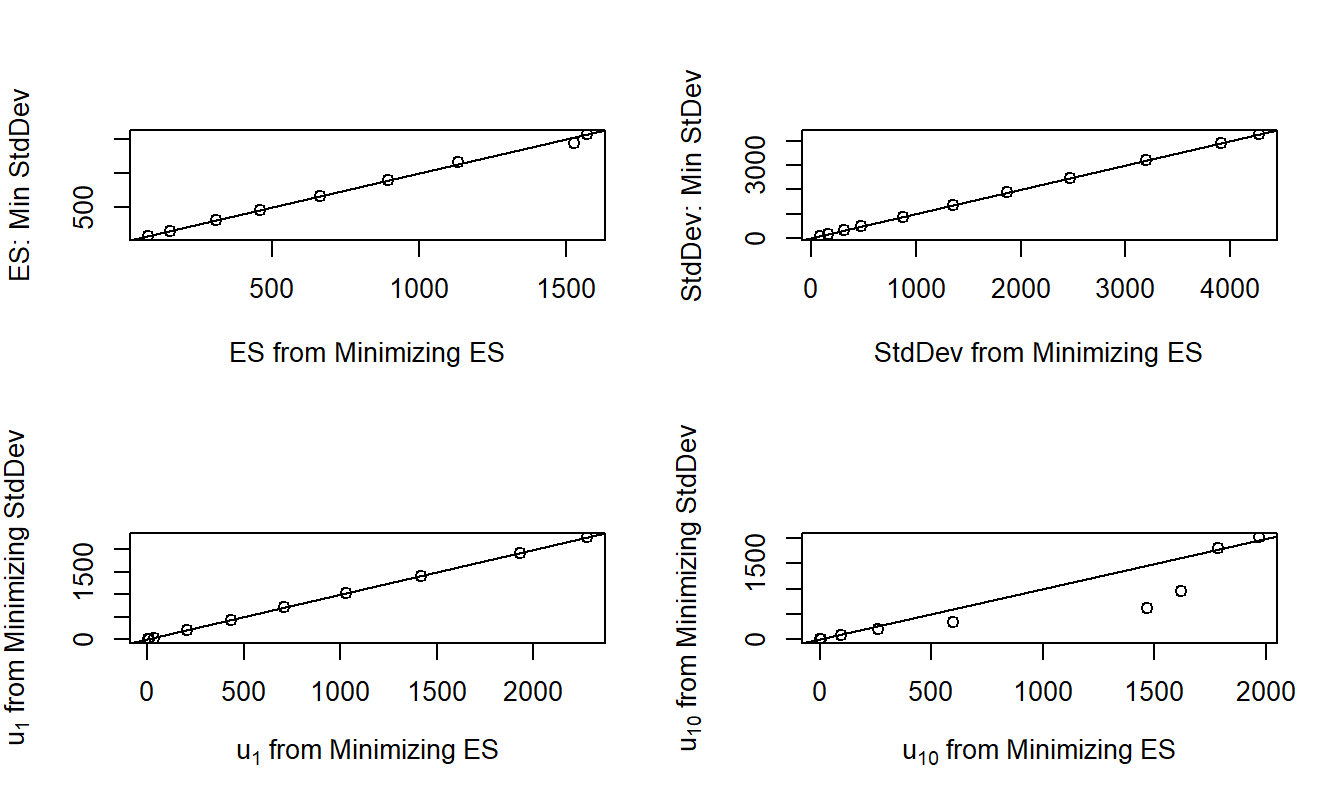
Figure 7.3: Comparison of Risk Measures and Retention Parameters by Optimization Method
One can summarize the relationships given in the Figure 7.3 panels using correlation statistics, such as shown in Table 7.5. Here, a correlation close to one suggests a linear relationship, that is, a close relationship for each retention parameter constructed using different objective functions. From the table, we see that although there are some differences when using different objective functions, there is substantial agreement for each of the 14 risks. I follow up with this in Appendix Section 7.7.3 where standard deviation minimization is employed to provide starting values for expected shortfall minimization.
| Param | \(u_{1}\) | \(u_{2}\) | \(u_{3}\) | \(u_{4}\) | \(u_{5}\) | \(u_{6}\) | \(u_{7}\) |
| Correlation | 1 | 0.999 | 0.97 | 0.976 | 0.98 | 0.954 | 0.997 |
| Param | \(u_{8}\) | \(u_{9}\) | \(u_{10}\) | \(u_{11}\) | \(u_{12}\) | \(u_{13}\) | \(u_{14}\) |
| Correlation | 0.999 | 0.976 | 0.927 | 0.945 | 0.984 | 1 | 0.948 |
Video: Section Summary
7.5 General Risk Retention Functions
Section 7.4 described simulation strategies to optimize our first nonlinear risk transfer agreement, the excess of loss. Having done so, similar strategies can be applied to a host of other risk transfer agreements. To distinguish among alternative agreements, this section describes general risk retention functions that are of interest to risk managers. In this book, we have used the notation \(g(\mathbf{X}; \boldsymbol \theta)\) to represent a risk owner’s retained risk after a risk transfer agreement \(g(\cdot; \cdot)\) based on multivariate risks \(\mathbf{X} = (X_1, \ldots, X_p)\) and a given set of risk retention parameters \(\boldsymbol \theta\). This section describes different categories of risk transfer agreements.
7.5.1 Separate Contracts for each Risk
One way to think about a firm’s risk retention policy is to postulate a different contract for each risk so that the amount retained for the \(j\)th risk is of the form \(g_j(X_j; \boldsymbol \theta_j)\). Many cases of interest also assume an additive structure among retained risks so that the total retained risk can be expressed as \[\begin{equation} g(\mathbf{X}; \boldsymbol \theta) = \sum_{j=1}^p g_j(X_j; \boldsymbol \theta_j) . \tag{7.10} \end{equation}\] As examples, we have already considered the quota share agreement with \(\theta_j = c_j\) and \(g_j(X_j; c_j) = c_j \cdot X_j\) as well as the excess of loss agreement with \(\theta_j = u_j\) and \(g_j(X_j; u_j) = X_j \wedge u_j\). The extension in equation (7.10) allows some of the contracts to be excess of loss and others to be quota share, as in Example 7.1. Also recall that with Chapter 2 based on univariate risks (\(p=1\)), in equation (2.6) we considered a risk retention function with three risk retention parameters, \(\boldsymbol \theta = (d, c,u)\) where \(d\) is the deductible, \(c\) is the coinsurance amount, and \(u\) is the upper limit of retention. Some risks may have deductibles, coinsurance, and upper limits.
Working with additive structures simplifies the numerical convergence of our optimization procedures. Moreover, as we will see in Chapter 11, an additive structure will simplify the analysis of conditions for when risk transfers achieve optimal values.
Note that the contracts represented by the risk transfer agreements \(g_j(\cdot)\) may or may not be with different vendors. If a vendor takes on a set of risks, other risks are irrelevant from that vendor’s perspective and may be treated as independent. Nonetheless, from the perspective of the risk owner, the risks themselves may still be dependent.
7.5.2 Combining Risks
Naturally, there will also be many instances when it is not possible to consider different risks additively. Rather than attempt to enumerate the infinite number of possible nonlinear combinations, this section describes selected examples of interest.
Example 7.7. Combined Deductibles from Bundled Insurance Contracts. In personal insurance, combined deductibles are common when insurers “bundle” together several types of insurance that had historically been offered separately, see, for example, Dong, Frees, and Huang (2022). For example, in travel insurance \(X_1\) might represent the loss due to luggage damage and \(X_2\) is the loss due to personal injury. Then, a type of insurance policy covers \[ Y_{insurer} = \left[ (X_1-d_1)_+ + (X_2-d_2)_+ - d_{combined} \right]_+ . \] In this expression, \(d_1\) is the deductible for luggage claims and \((X_1-d_1)_+\) is the luggage excess. In the same way, \(d_2\) is the deductible for personal injury and \((X_2-d_2)_+\) is the personal injury excess. The insurer is responsible for the excess over a combined deductible, \(d_{combined}\), over these two separate excesses. Note that these are “deductibles” from the perspective of the insurer but can also be viewed as upper limits from an individual’s perspective.
Example 7.8. Global Protections Coverage. As described in Section 4.1.4, agreements between an insurer and a reinsurer can cover multivariate risks in a nonlinear way. To illustrate, in that section we introduced an agreement where the reinsurer’s portion of the total risk is \[ Y_{reinsurer} = \min \left( \sum_{j=1}^p \min[(X_j-u_{1,j})_+, u_{2,j}], AAL \right) . \] Here, \(u_{1,j}\) represents a reinsurer’s deductible, \(u_{2,j}\) represents is upper limit for the \(j\)th risk, and \(AAL\) stands for the annual aggregate limit \(AAL\). Also as noted in that section, Albrecher, Beirlant, and Teugels (2017) refers \(AAL\) as a type of global protections.
Example 7.9. Separate Coverages by Peril. Sometimes risks are split by cause of loss, also known as peril, with different arrangements such as sublimits made for each peril. Sublimits by peril are common in property and casualty insurance. For example, the ANU property risk, described in Appendix Section 8.3.4, is subdivided into two parts, each having different sets of sublimits. One part is for material loss or damage that covers real and personal property in which ANU has an insurable interest. The second part is for consequential loss that covers other damages suffered by ANU resulting from the interruption or interference of business. See Frees and Butt (2022) for more information about ANU sublimits.
To illustrate in a simple setting, one might introduce a sublimit \(u_1\) that limits how much of risk \(X_1\) can be transferred. Then, if \(X_2\) represents all other risks and \(u_{overall}\) is an overall limit, we can use \[ Y_{firm} = \left( X_1 \wedge u_1 + X_2 \right) \wedge u_{overall} \] to express the amount retained by a firm.
7.5.3 Frequency Severity Approaches to Modeling Risks
For risks that occur frequently in a calendar period, it is convenient to define risk transfers on a per event or per occurrence of a claim basis. So, instead of working directly with \(X_j\), the overall type \(j\) loss amount, we might decompose this into a number of claims in a year, say \(N_j\), and examine each individual claim outcome, \(X_{j1}, \ldots, X_{jN_j}\). This is sometimes known as the collective risk model, cf. Actuarial Community (2020), Chapter 5. With the collective model approach, we express aggregate type \(j\) losses as \(X_j = \sum_{i=1}^{N_j} X_{ji}\).
As an example, it is common for a large firm, the risk owner, to maintain a fleet of motor vehicles where insured claims occur with a high frequency. In this case, it is common to define risk transfer mechanisms (such as deductibles and upper limits) for each claim. For example, a firm might retain claims up to \(u_j\) and so the total retained claims is \[ Y_{j,retained} = \sum_{i=1}^{N_j} X_{ji} \wedge u_{j} . \] As another example, suppose that an insurer provides protection to a large firm that has many buildings. As described in Section 4.1.4, the amount transferred to the insurer may be of the form \[ Y_{j, transfer} = \left[\sum_{i \in \text{event}} (X_{ji}-d_{j})_+\right] \wedge u_j . \] For each building claim, \((X_{ji}-d_{j})_+\) represents the amount in excess of a deductible \(d_j\). The sum within the square braces is the total excess for all claims but the transferred amount is limited by \(u_j\). Analysis of this type of insurance protection is especially difficult when the buildings are concentrated geographically (such as buildings owned by a university) and there can be many claims due to a common event such as an earthquake or hurricane.
For the collective risk model, analysis by peril is a bit more complicated because, for an individual claim, only one of several types of perils can occur. See Frees, Meyers, and Cummings (2010) for further discussion of this model.
7.5.4 Comparing Risk Retention Functions
As described in this section, there can be many candidate risk retention plans depending on the nature of the risks. In addition, the experience of the risk manager and industry norms can also play important roles in selecting a risk retention plan.
As summarized in this chapter, optimal parameter values of each risk retention plan can be determined. However, risk retention parameters are not directly comparable as they quantify different types of contributions to retained risk. What can be quantified and compared is the overall measure of retained risk uncertainty.
For example, Figure 7.4 shows expected shortfall versus maximal risk transfer costs for two risk retention plans, the quota share problem described in Example 7.4 and the excess of loss problem described in Section 7.4.1. Both use the same distributions based on fourteen risks from the ANU case. Figure 7.4 shows that the solid blue plotting symbols, corresponding to quota share, are consistently higher than the open red symbols corresponding excess of loss. The ratio difference can be as large as 12 percent for the middle values of \(RTC_{max}\). Although some risk managers may have difficulty in interpreting an expected shortfall, the interpretation of a 12 percent reduction in uncertainty (by moving from quota share to excess of loss) can be appealing.
R Code for Section 7.5.4
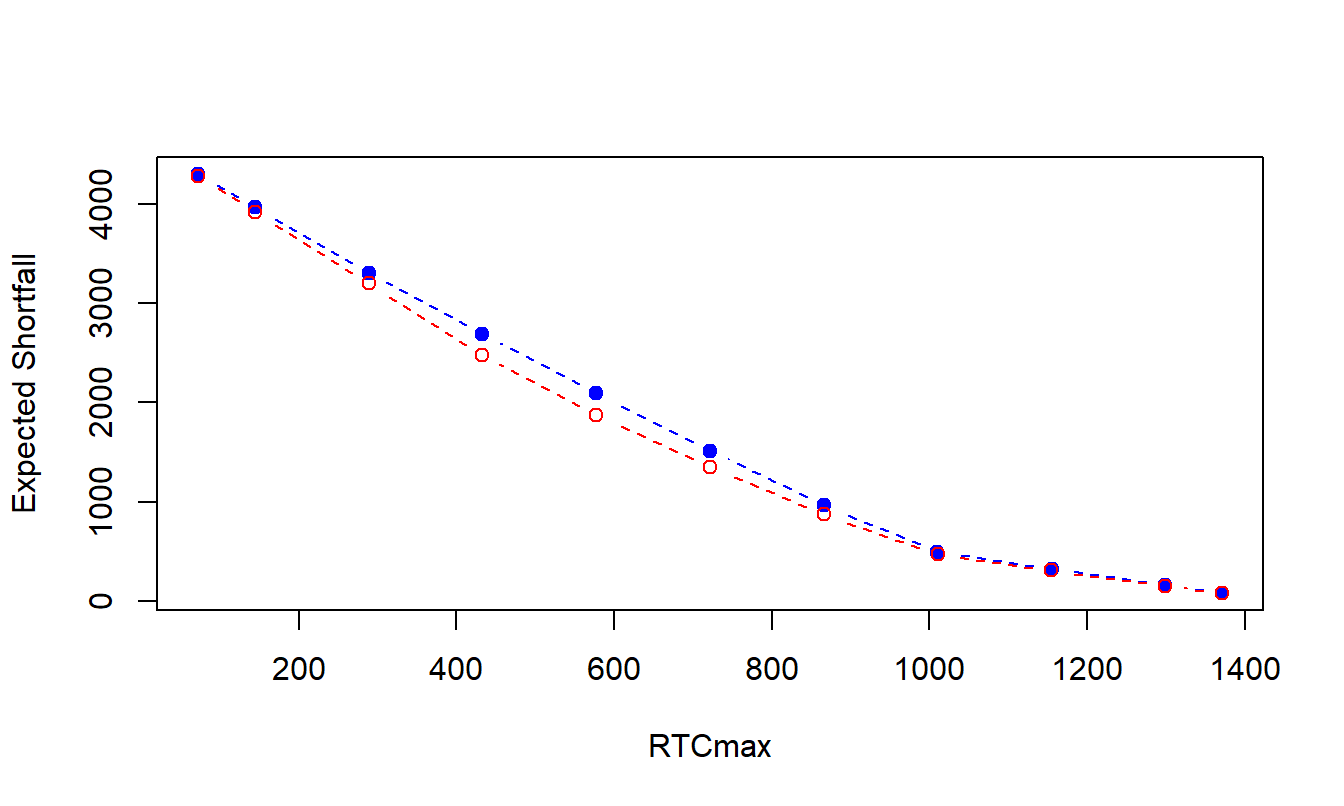
Figure 7.4: Comparison of Expected Shortfall Frontiers from Excess of Loss and Quota Share Programs
7.5.5 Market Loading of Risk Transfer Costs
This section has focused on extensions of risk retention functions needed to determine optimal risk transfer solutions. To promote interpretability, I have focused the development on fair risk transfer costs. Naturally, to implement these procedures, adjustments to fair costing will be needed in order to reflect administrative expenses and the market availability of coverages.
So, as a small extension of the fair risk transfer costs, one can consider market loadings (\(ML\)) of risk transfer costs. These are exogenous coefficients for which equation (7.11) gives two ways of introducing market loadings. In the first expression, we consider the portfolio as a whole and so this may be an adjustment for overall administrative expenses that are common to all risk types. To motivate the second approach, one might assume that the portfolio risk transfer costs can be subdivided into separate contracts as in Section 7.5.1. In this case, we can think about different market loadings for each risk (\(ML_j\)) and use \[\begin{equation} RTC_R(\boldsymbol \theta) = \left\{ \begin{array}{ll} \frac{ML}{R} \sum_{r=1}^R \left\{ \left( \sum_{j=1}^p X_{rj} \right) - g({\bf X}_{r};\boldsymbol \theta) \right\} \\ \frac{1}{R} \sum_{r=1}^R \left\{ \sum_{j=1}^p ML_j [X_{rj} - g_j({\bf X}_{r};\boldsymbol \theta_j) ] \right\} \end{array} \right. . \tag{7.11} \end{equation}\] In some exercises that follow, such as Exercise 8.7 on varying a cyber risk premium, I implement these simple adjustments. Naturally, there are other methods of determining risks transfer costs, such as using quantiles in lieu of expectations for costing, that the reader is invited to explore.
Video: Section Summary
7.6 Simulation Uncertainty
As seen in Chapter 5, with only two risks we are able to use precise deterministic methods to construct optimal insurable risk portfolios. When the number of risks is larger than two, simulation methods become preferred and are the focus of this chapter (and the remainder of the book). However, simulation methods introduce uncertainty and risk managers want some assurance that recommendations are not being clouded by unpredictable errors introduced by this calculation technique.
As analysts, we know that simulation methods typically converge to deterministic quantities due to the law of large numbers. However, these results do not help analysts decide how large a sample size, \(R\), to use. There is, of course, a trade-off; larger values of \(R\) are more accurate but take longer to compute. For practicing analysts, one approach is to use a smaller number of replications during the design phase of a study when broad patterns and tendencies are of interest. Later, at the final stages of the study when precision is paramount, a greater number of replications can be used to enhance the reliability of the study.
To calibrate the size of simulation uncertainty, one option is to use central limit theorem results to get estimates of the size of simulation errors, cf. Actuarial Community (2020), Chapter 6. In addition, to reassure risk managers that simulation uncertainty has been addressed, this section demonstrates the use of resampling techniques to show effects of simulation uncertainty.
To assess simulation variability, I generated 20 independent samples of the ANU distribution, each of size 5,000. The sample size 5,000 is small relative to other simulation applications; with this relatively small number we can visualize the uncertainty induced by simulation. For each sample, I determined optimal values of the upper limits over a range of maximal risk transfer costs.
Figure 7.5 summarizes the results. The left-hand panel shows the risk transfer cost \(RTC\) versus the expected shortfall \(ES\) for each level of \(RTC_{max}\). In the same way, the middle and right-hand panels show optimal values of the first two optimal retention parameters, \(u_1\) and \(u_2\). At each level, there are 20 points plotted, each corresponding to a different simulation scenario. For these runs, it turned out that the \(RTC\) equals the maximal value \(RTC_{max}\) so this constraint is binding.
For large values of \(RTC\), it is difficult to distinguish among the different values of \(ES\), \(u_1\) and \(u_2\), suggesting that using only \(R=5,000\) simulations is adequate. For small values of \(RTC\), the figure provides an indication of the uncertainty imposed by the simulation. If one is dealing with a situation where most of the risk is being retained but a great deal of precision is needed, one should increase the number of simulations to increase the precision. The strength of the type of display in Figure 7.5 is that the simulation uncertainty is interpretable for a risk manager and can help to provide comfort when interpreting results from simulation optimization techniques.
R Code for Minimizing ES for Several Subsamples
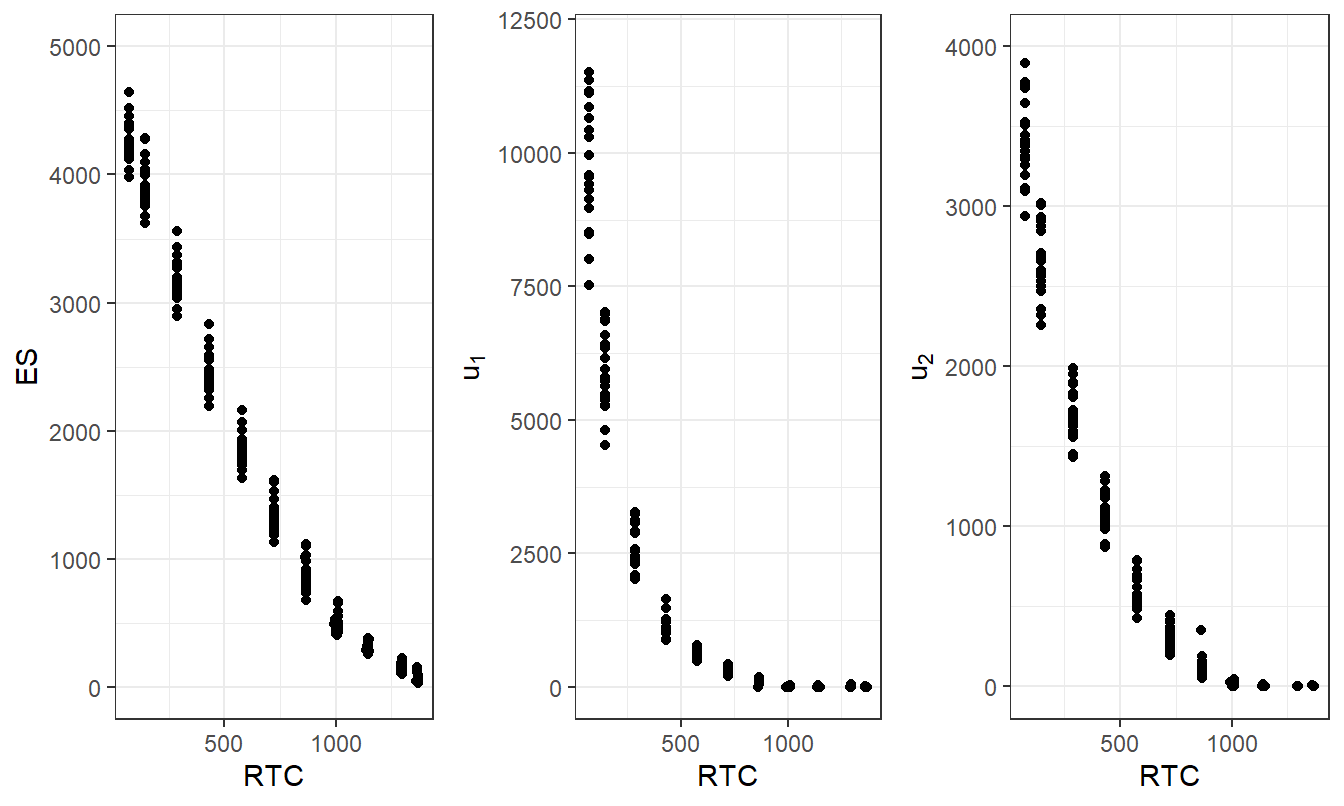
Figure 7.5: ANU Excess of Loss Optimization Results for Several Subsamples
A similar type of resampling technique that can show simulation uncertainty is a bootstrap method. For example, I started with a large number of replications, \(R=100,000\), and then resampled (with replacement) from this initial sample to generate \(B=10\) bootstrap replicates. Each bootstrap replicate is optimized and the variability among these optimizations can be used to portray simulation uncertainty, similar to Figure 7.5. This output is not provided because, as it turns out, there was practically no simulation uncertainty in such a graph due to the large number of initial replicates, \(R=100,000\). This type of exercise provided motivation for selecting \(R=100,000\) as the basis for the examples in this chapter so that readers need not worry about simulation error. An exercise asks readers to verify this finding.
Video: Section Summary
7.7 Supplemental Materials
7.7.1 Further Resources and Reading
As noted earlier, for readers wanting a refresher in simulation techniques, see the online book Actuarial Community (2020), Chapter 6. In addition, this book provides a short introduction to kernel estimation in Section 4.1.
The approach used in this book is based on minimizing a function that is approximated using simulation. In the operations research literature, this is known as sample average approximation. See, for example, Shapiro (2013) for a brief introduction or Kim, Pasupathy, and Henderson (2015) for a more detailed introductory guide. Within this literature, there are many variations of this basic approach that may be employed to improve the initial efforts presented here. In particular, I have adopted a smoothing approach based on kernel estimation in Section 7.3. Smoothing of non-continuous functions has been described more broadly, cf. Fu (2015b), with kernel estimation being a specific case. For example, Liu and Hong (2009) uses kernel estimation to derive quantile sensitivities. See Givens and Hoeting (2013) for a background on kernel estimation, including computational considerations.
The quota share model that was discussed in Section 7.2.3 had been put forth earlier in Sun, Weng, and Zhang (2017). This paper worked, not using simulation, but in a more general context of nonparametric estimation, including the kernel techniques described in Section 7.3.
7.7.2 Exercises
Section 7.1 Exercises
Exercise 7.1. Quantile Regression Approach. Many data analysts have some familiarity with quantile regression. As the name suggests, this is a technique for determining the value at risk, or quantile, in the presence of linear covariates. See, for example, Koenker (2005). The goal of this exercise is to establish the equivalence between this approach and the \(ES\) minimization in Display (7.4), at least for risk retention problems of interest to us.
a. Define a function \(\phi_{\alpha}(y) = 0.5 |y| + \left(\alpha - 0.5\right) y\) that is known as loss function in classical statistics. Consider a generic random variable \(Y\) having distribution function \(F\) that has a unique value, \(F^{-1}(\alpha)\), for its \(\alpha\) quantile. Check that \(F^{-1}(\alpha)\) is the solution of the unconstrained minimization problem \[ \boxed{ \begin{array}{lc} {\scriptsize{\text{minimize}_{z_0}}} & ~~~~~\mathrm{E~}\phi_{\alpha}(Y-z_0) \end{array} } \]
b. Now, suppose that we have i.i.d replications of \(Y_r = g({\bf X}_{r};\boldsymbol \theta)\), \(r = 1, \ldots, R\). Show that one can summarize the quantile regression retention problem as: \[\begin{equation} \boxed{ \begin{array}{lc} {\scriptsize{\text{minimize}_{z_0,\boldsymbol \theta}}} & \mathrm{E}_R ~\phi_{\alpha}[g({\bf X};\boldsymbol \theta)-z_0] \\ {\scriptsize \text{subject to}} & ~~~~~RTC_R(\boldsymbol \theta) \le RTC_{max} .\\ \end{array} } \tag{7.12} \end{equation}\]
c. To see that the expected shortfall problem is essentially identical to the regression quantile risk problem, consider the following.
- In Display (7.12), we seek to minimize the objective function \(f_{QR,0}(z_0, \boldsymbol \theta) = \mathrm{E}_R~ \phi_{\alpha}[g({\bf X};\boldsymbol \theta)-z_0]\).
- In Display (7.4), we seek to minimize the objective function \(f_{ES,0}(z_0, \boldsymbol \theta) =z_0 + \frac{1}{(1-\alpha)} \mathrm{E}_R [g({\bf X};\boldsymbol \theta) - z_0]_+\).
Show that these are related through the expression \[\begin{equation} f_{ES,0}(z_0, \boldsymbol \theta) = \mathrm{E}_R ~g({\bf X};\boldsymbol \theta) + \frac{1}{1-\alpha} f_{QR,0}(z_0, \boldsymbol \theta) . \tag{7.13} \end{equation}\]
\(Under~the~Hood.\) Show the Solution for the Quantile Regression Approach Exercise
Equation (7.13) implies that the optimal value \(z_0^*\) is the same for both procedures. We defer the demonstration of the equivalence between these two methods for the other decision variables to Exercise 11.5 where it arises naturally as part of a discussion on risk transfer conditions.
Exercise 7.2. No Kernel Smoothing: Simulated Expected Shortfall Derivatives. Consider the simulation version of the expected shortfall objective function without kernel smoothing. Specifically, as in Display (7.4), use an objective function that depends on \({\bf z} = (z_0, \boldsymbol \theta)'\) decision variables and can be expressed as \[ ES1_R({\bf z}) = z_0 + \frac{1}{(1-\alpha)} \mathrm{E}_R~ \{ \left[g({\bf X};\boldsymbol \theta) - z_0\right]_+ \}. \]
a. Show that the gradient is \(\partial_{\bf z} ~ES1_R({\bf z}) = (\partial_{z_0}~ES1_R(z_0, \boldsymbol \theta),\partial_{\boldsymbol \theta}~ES1_R(z_0, \boldsymbol \theta))\) where \[ \partial_{z_0}~ES1_R({\bf z}) =1 - \frac{1}{1-\alpha} \mathrm{E}_R~ \{I\left[g({\bf X}; \boldsymbol \theta) >z_0 \right]\} \] and \[ \partial_{\boldsymbol \theta}~ES1_R({\bf z}) =\frac{1}{1-\alpha}\mathrm{E}_R~ \{I\left[g({\bf X}; \boldsymbol \theta) > z_0\right] \partial_{\boldsymbol \theta} g({\bf X}; \boldsymbol \theta)\} .\\ \]
b. Show that the Hessian is \[ \partial_{\bf z}\partial_{\bf z'}~ES1_R({\bf z}) = \left( \begin{array}{cc} 0& {\bf 0}' \\ {\bf 0} & \partial_{\boldsymbol \theta} \partial_{\boldsymbol \theta'}~ES1_R(z_0, \boldsymbol \theta) \end{array} \right) , \] where \[ \partial_{\boldsymbol \theta} \partial_{\boldsymbol \theta'}~ES1_R(z_0, \boldsymbol \theta) =\frac{1}{1-\alpha}\mathrm{E}_R~ \{I\left[g({\bf X}; \boldsymbol \theta) >x \right] \partial_{\boldsymbol \theta} g({\bf X}; \boldsymbol \theta) \partial_{\boldsymbol \theta'} g({\bf X}; \boldsymbol \theta) \}.\\ \] Note, from this expression, that the Hessian is not invertible.
Show Exercise 7.2 Solution
Section 7.2 Exercises
Exercise 7.3. Quota Sharing of ANU Risks. To see how this works, let us revisit the ANU Risk Data, as in Example 7.4. Replicate the results in Table 7.6 that summarizes optimization results which extends results from Example 7.4 over a range of costs. As in Example 7.4, the minimization is done over the set of allocations \(c_1, \ldots, c_{14}\) although only the first three quota share coefficients are printed, for brevity. Optimization calculations should be done using the R convex optimization package CVXR.
R Code Solution for Exercise 7.3
| \(RTC_{max}\) | \(RTC\) | \(VaR\) | \(ES\) | \(Std\) \(Dev\) | \(c_1\) | \(c_2\) | \(c_3\) |
|---|---|---|---|---|---|---|---|
| 1371.2 | 1371.2 | 78.7 | 81.4 | 5.1 | 0.000 | 0.000 | 0.000 |
| 1299.0 | 1299.0 | 157.5 | 162.7 | 10.3 | 0.000 | 0.000 | 0.000 |
| 1154.7 | 1154.7 | 319.2 | 332.8 | 24.2 | 0.000 | 0.000 | 0.000 |
| 1010.4 | 1010.4 | 487.7 | 510.7 | 42.5 | 0.000 | 0.000 | 0.000 |
| 866.0 | 866.0 | 787.9 | 1187.9 | 312.7 | 0.020 | 0.136 | 0.126 |
| 721.7 | 721.7 | 1169.3 | 2004.5 | 636.1 | 0.054 | 0.369 | 0.345 |
| 577.3 | 577.3 | 1574.3 | 2876.3 | 973.3 | 0.096 | 0.650 | 0.610 |
| 433.0 | 433.0 | 1992.9 | 3764.8 | 1314.8 | 0.138 | 0.939 | 0.885 |
| 288.7 | 288.7 | 2346.8 | 4765.8 | 1734.7 | 0.377 | 1.000 | 1.000 |
| 144.3 | 144.3 | 2583.1 | 5954.1 | 2263.0 | 0.688 | 1.000 | 1.000 |
| 72.2 | 72.2 | 2681.6 | 6576.2 | 2546.1 | 0.844 | 1.000 | 1.000 |
Exercise 7.4. Quota Sharing of ANU Risks Minimizing the Variance. This is a continuation of Exercise 7.3 but now minimizing the variance, not the expected shortfall. Provide R code to determine quota share allocations when minimizing the variance. The results are not displayed because of their similarity to Table 7.6.
R Code Solution for Exercise 7.4
Exercise 7.5. Comparing Quota Sharing of ANU Risks Using Different Objective Functions. In this exercise, you will compare results from Exercise 7.3 based on the (auxiliary) expected shortfall objective function to those of Exercise 7.4 based on the variance objective function. To show the similarity among the results, provide a graph similar to Figure 7.6 that compares values of \(VaR\), \(ES\), and two of the quota share parameters, \(c_1\) and \(c_2\).
We learned in Section 7.2.3 that results would be exactly the same for elliptically distributed risks yet have no theory for non-elliptical risks such as the ANU data. This exercise reinforces the observations made in Example 7.4, extending the analysis to a range of values of \(RTC_{max}\).
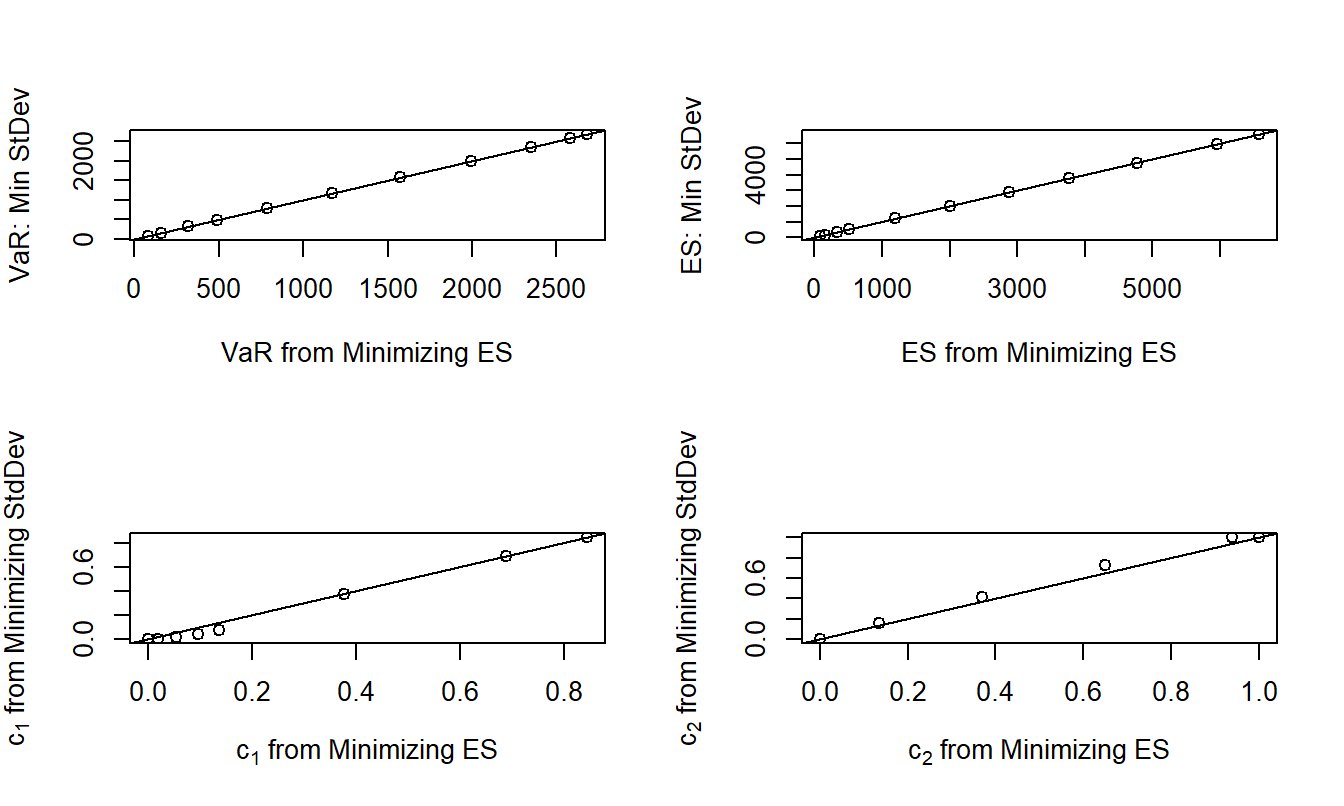
Figure 7.6: Comparison of Risk Measures and Allocation Parameters from Different Objective Functions
Section 7.3 Exercises
Exercise 7.6. Kernel Smoothing of Expectations, with Derivatives. Consider the simulation version of the expectations, including expected shortfall, with kernel smoothing.
a. Verify the expression in equation (7.5).
b. Verify the expression in equation (7.6).
c. Show that the gradient is \(\partial_{\bf z} ~ES1_{Rk}({\bf z}) = (\partial_{z_0}~ES1_{Rk}(z_0, \boldsymbol \theta),\partial_{\boldsymbol \theta}~ES1_{Rk}(z_0, \boldsymbol \theta))\) where \(\partial_{z_0}~ES1_{Rk}(z_0, \boldsymbol \theta)\) is given in equation (7.7) and \(\partial_{\boldsymbol \theta}~ES1_{Rk}(z_0, \boldsymbol \theta)\) is given in equation (7.8).
Show Exercise 7.6 Solution
Exercise 7.7. Kernel Smoothed Expected Shortfall Hessian. Provide an expression for the Hessian associated with kernel smoothed version of the expected shortfall. From the solution, you will see that this matrix is generally invertible, in contrast to the Hessian derived in Exercise 7.2.
Show Exercise 7.7 Solution
Exercise 7.8. Value at Risk with Kernel Smoothing. Consider the simulation version of the value at risk with kernel smoothing. Define kernel smoothed value at risk \(VaR_{Rk}\) as the solution of the equation \(F_{Rk}(y) = \alpha\). Further consider an excess of loss retention scheme with \(\boldsymbol \theta = (u_1, \ldots, u_p)\). Show that the partial derivatives can be expressed as \[ \begin{array}{ll} \partial_{\bf u}VaR_{Rk} &= \left. \left\{\sum_{r=1}^R ~k\left(\frac{y - S_r({\bf u})}{b}\right)\left(\begin{array}{c}I(X_{1r} > u_1) \\ \vdots \\ I(X_{pr} > u_p) \end{array}\right) \right\} \left[\sum_{r=1}^R ~k\left(\frac{y - S_r({\bf u})}{b}\right) \right]^{-1} \right|_{y=VaR_{Rk}} , \end{array} \] that is, a weighted average.
Show Exercise 7.8 Solution
Section 7.6 Exercise
Exercise 7.9. Bivariate Excess of Loss Using \(ES\) Optimization. Let us demonstrate the simulation uncertainty introduced in Section 7.6 but in a simpler context than the ANU data. Specifically, consider the distribution introduced in Example 7.3 that considers two risks that depend on one another through a Gaussian copula with dependence parameter \(\rho =\) 0.5. The first risk is \(X_1\), with a gamma distribution having shape parameter 2 and scale parameter 2,000, and the second is \(X_2\), with a Pareto distribution having shape parameter 3 and scale parameter 2,000. A level of confidence \(\alpha =\) 0.95 is used.
Replicate the work summarized in Figure 7.7. This was produced using 10 independent samples, each of size 10,000.
R Code Solution for Exercise 7.9
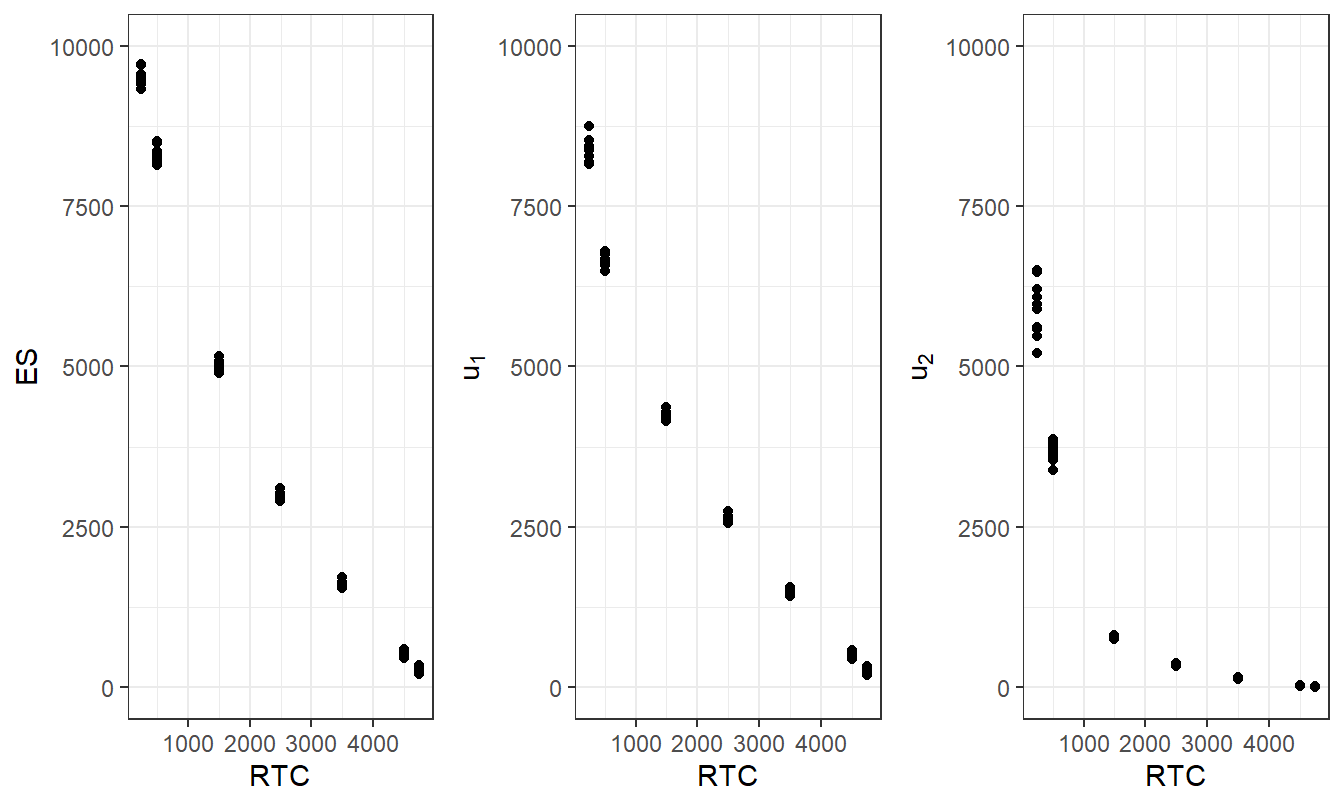
Figure 7.7: Gamma Pareto Excess of Loss Optimization Results for Several Subsamples
7.7.3 Appendix. Starting Values for Multivariate Excess of Loss
We use numerical methods to solve constrained optimization problems as in Display (7.9). This problem is not in general convex and because of the large number of decision variables (\(p=14\) for the ANU case study), the optimization task is immensely simplified with good starting values. As suggested in Section 7.2.3, one approach to determine starting values is to utilize the variance as a risk measure. By making additional simplifying assumptions of independence among risks and assuming the constraint is active, we can rely on some classic results from the actuarial literature, as follows.
For numerical work, it helps to rescale risks. To this end, define scale factors \(sd_j\) and rescaled risks \(X_j^s = X_j/sd_j\), \(j= 1, \ldots, p\). You can think of \(sd\) as a standard deviation although it need not be.
With the rescaled risks and an active constraint, we seek to solve the problem \[\begin{equation} \boxed{ \begin{array}{lc} {\small \text{minimize}_{u_1^s, \ldots, u_p^s}} & \sum_{j=1}^p \mathrm{Var}(X_j^s \wedge u_j^s) \\ {\small \text{subject to}} & RTC(u_1^s,\ldots, u_p^s) = RTC_{max}^s . \end{array} } \tag{7.14} \end{equation}\] Using the method of Lagrange multipliers, one can show that the solution is \[\begin{equation} \begin{array}{llc} LME^s &= 2 (u_j^s - E[X_j^s \wedge u_j^s]) & j=1, \ldots, p \\ RTC_{max}^s &= \sum_{j=1}^p ~\mathrm{E}(X_j^s)-\mathrm{E}(X_j^s \wedge u_j^s)] . \end{array} \tag{7.15} \end{equation}\] The first result of this fashion that I am aware of appears in Bühlmann (1970), Section 5.2.2.
\(Under~the~Hood.\) Confirm Display (7.15)
Display (7.15) is a system of \(p+1\) equations having \(p+1\) unknowns, \(\{LME^s, u_1^s, \ldots, u_p^s \}\), that can be solved via direct substitution. To this end, define the scaled distribution function \(F_{j}^s(x) = \Pr(X_j^s \le x) = F_{j}(x \times sd_j)\) and the corresponding integrated distribution function \[ H_{j}^s(x) = \int_0^{x} F_j^s(z) dz = x -\int_0^{x} [1-F_j^s(z)] dz= x-E (X_j^s \wedge x). \] With this notation, we may determine \(LME^s\) as the solution of the equation \[\begin{equation} \sum_{j=1}^p ~\mathrm{E}(X_j^s) - RTC_{max}^s = \sum_{j=1}^p \left\{ H_{j}^{-1s}\left(\frac{LME^s}{2}\right) - \frac{LME^s}{2} \right\} . \tag{7.16} \end{equation}\] With a value of \(LME^s\), we can then calculate the optimal scale retention limits using \(u_j^s = H_{j}^{-1s}(\frac{LME^s}{2})\).
\(Under~the~Hood.\) Confirm Equation (7.16)
After solving this problem, we revert to the original scale and define the rescaled upper limits to be \(u_j^{rs} = sd_j \times u_j^s\). For the scaled problem, we know from the first line of Display (7.15) that the separation between the upper bound and its limited expected value, \(u_j^s - \mathrm{E}(X_j^s \wedge u_j^s)\), is constant for all risks. However, reverting to the original scale \[ sd_j\left[u_j^s - \mathrm{E}(X_j^s \wedge u_j^s) \right] = u_j^{rs} - \mathrm{E}(X_j \wedge u_j^{rs}) , \] this gap is larger for risks with larger scale factors. This seems to be intuitively desirable.
To select a value of \(RTC_{max}^s\), we propose \(RTC_{max}^s = RTC_{max}/\overline{sd}\), where \(\overline{sd} = \frac{1}{p}\sum_{j=1}^p sd_j\) is the average value of the scale factors.
\(Under~the~Hood.\) Confirm the Scaling Factor to Maintain the Budget Constraint
The results are summarized in Table 7.7. We remark that when we used the classical result without scaling and including the property risk, the starting values produced were not helpful. Intuitively, this is because the gap for property risk is the same as for all the small risks, producing very large upper limits for those smaller risks. As a consequence, use of these starting values caused the constrained optimization algorithms to fail. The rescaling method did allow us to determine sensible starting values when including property (although we ultimately excluded property from the optimization as described above).
R Code for Starting Values
| \(RTC_{max}\) | \(LME\) | \(SV_{u1}\) | \(SV_{u2}\) | \(SV_{u3}\) | \(SV_{u4}\) | \(SV_{u5}\) | \(SV_{u6}\) |
|---|---|---|---|---|---|---|---|
| 1374 | 0 | 47 | 6 | 7 | 6 | 1 | 14 |
| 1302 | 0 | 79 | 11 | 12 | 10 | 1 | 16 |
| 1157 | 1 | 191 | 28 | 29 | 25 | 3 | 18 |
| 1013 | 2 | 387 | 59 | 62 | 54 | 6 | 20 |
| 868 | 5 | 700 | 112 | 118 | 101 | 12 | 22 |
| 723 | 9 | 1164 | 195 | 205 | 176 | 20 | 24 |
| 579 | 14 | 1825 | 318 | 334 | 287 | 33 | 27 |
| 434 | 23 | 2785 | 501 | 526 | 453 | 52 | 31 |
| 289 | 37 | 4300 | 792 | 832 | 716 | 83 | 36 |
| 145 | 64 | 7147 | 1337 | 1403 | 1207 | 140 | 47 |
| 72 | 93 | 10158 | 1905 | 2000 | 1720 | 199 | 57 |