Chapter 2 Risk Retention Functions
Chapter Preview. In Chapter 1, risk transference emerges as a vital managerial tool. Risk transfer agreements split risk: one part remains with the owner, while the rest shifts to others at a cost. A risk retention function determines this division of risk. When insurance is used for risk transference, the standard retention functions are sometimes referred to as “modifications” of a base risk. Classic examples of insurance coverage modifications include imposing a deductible where small risks are not covered, a coinsurance where only a fraction of a risk is covered, and an upper limit that restricts the impact of a large risk. Deductibles, coinsurances, and upper limits are examples of risk retention parameters upon which a risk retention function is based.
To quantify the impact of risk transfer, this chapter lays the foundations by describing commonly used measures to quantify risk uncertainty. Risk owners want to understand the uncertainty of risks, both before and after a transfer. Risk owners are also concerned with the cost of offloading risks; for simplicity, this chapter emphasizes a “fair” cost based on expectations.
To lay the groundwork, this chapter restricts attention to a single risk that one can interpret to be the risk owner’s portfolio. Subsequent chapters will develop a structure to determine optimal choices of risk retention parameters. To provide the groundwork for these developments, this chapter quantifies changes in the measures of uncertainty and risk transfer costs based on changes in the risk retention parameters. It is convenient to use a differential approach when summarizing the effects of small changes in parameters; these effects are known as sensitivities.
2.1 Measures of Uncertainty
To evaluate alternative risk transfer options, the risk owner’s manager needs principles for determining amounts of risk before and after the transfer, as well as the cost of a risk transfer. Of course, the exact reduction in obligations only becomes known once all financial obligations are settled at the contract’s conclusion. During the decision-making process, only a distribution of potential risk outcomes is available.
As with any random variable, tools such as the distribution function provide analysts with an understanding of the potential outcomes’ distribution. Risk managers are especially concerned with the uncertainty of the potential outcomes for which there are several commonly used measures. Because of its simplicity, historically the most commonly used measure has been the variance, \(\mathrm{Var}(X) = \mathrm{E} [X - \mathrm{E}(X)]^2\), and its positive square root, the standard deviation.
In a broad context, a risk measure is a mapping of a loss random variable to a numerical value that indicates its level of uncertainty. Managers utilize risk measures as a guide to determine the necessary asset reserves for covering contingent losses stemming from risks. For an introductory overview of risk measures, refer to the online book Actuarial Community (2020), Chapter 10.
In our development we focus on risk measures that are based on quantiles of a random variable. As indicated in Section 1.4.1, the primary measure is the value at risk (\(VaR\)) which represents the quantile of \(X\). In other words, for a specific confidence level \(\alpha\), the \(VaR\) is the smallest value of \(x\) for which the associated distribution function is greater than or equal to \(\alpha\). Mathematically, we can write this as \[\begin{equation} VaR_{\alpha}[X] = \inf\{x:F_X(x)\geq \alpha \} , \tag{2.1} \end{equation}\] for \(0 \le \alpha \le 1\). Here, inf is the infimum, or greatest lower bound, operator. To emphasize the quantile nature of the \(VaR\), we sometimes use the notation \(VaR_{\alpha}[X] = F^{-1}_{\alpha}\) and occasionally write \(F^{-1}(\alpha)\) (for complex expressions in the place of the argument \(\alpha\)). Note on Notation: To distinguish the value of risk (\(VaR\)) from the variance (\(\mathrm{Var}\)), we follow a common practice in the literature and capitalize the R in the value at Risk. You will also see some sources that use \(V@R\) to promote this distinction.
Another commonly used quantile-based risk measure is the Expected Shortfall, \(ES\), that can be interpreted as an “average” value at risk. Mathematically, we can express this as \[\begin{equation} ES_{\alpha}(X) = \frac{1}{1-\alpha} \int_{\alpha}^{1} VaR_{a}(X) d a . \tag{2.2} \end{equation}\] Under some mild assumptions on the continuity of the distribution function, there are a few other forms of the \(ES\) that will be useful to us. As described in Section 2.5.1, one can show that \[\begin{equation} \begin{array}{lll} ES_{\alpha}(X) &= \frac{1}{1-\alpha} \int_{\alpha}^{1} VaR_{a}(X) d a & \text{Expected Shortfall}\\ &= F^{-1}_{\alpha} + \frac{1}{1- \alpha} \left\{ \mathrm{E} X - \mathrm{E} [X \wedge F^{-1}_{\alpha}] \right\} & \text{Tail VaR}\\ & = \mathrm{E} (X | X > F^{-1}_{\alpha}) & \text{Conditional VaR.} \end{array} \tag{2.3} \end{equation}\] From the third expression, we see that \(ES\) can also be interpreted to be the expected amount given that the loss exceeds the \(VaR_{\alpha}\). There is a bit of divergence in the literature, these closely related measures are also known as tail conditional expectation, conditional tail expectation, and expected tail loss, among others.
Another Note on Notation: The expected shortfall is denoted with capital italic letters as \(ES\). In contrast, the expectation operator is the capital roman letter \(\mathrm{E}(\cdot)\). These both represent common practice in the literature but, because notationally they are so similar, it is easy to confuse these two very different concepts.
\(Under~the~Hood.\) Show Development of the \(ES\)
Example 2.1. Property Fund Claims Distribution. To illustrate, we consider commercial property claims from the Wisconsin Property Fund, introduced in Section 1.2.2. These data can be accessed from the online book, Actuarial Community (2020), Chapter 22. This example is based on 1,377 claims from 2010 for damages to state government properties and their building contents.
These data were used to estimate an empirical distribution function, without reference to a parametric model. The empirical distribution function was then used to estimate \(VaR\) and \(ES\) over several confidence levels. Figure 2.1 summarizes these results. From the figure, we see that the two summary measures of uncertainty provide qualitatively similar results in that they increase in the same way as the confidence level \(\alpha\) increases. In addition, the right-hand panel compares the two measures - this comparison reminds us that, for any given level of confidence, that the \(ES\) measure typically exceeds the \(VaR\). (See the middle expression in Display (2.3).)
R Code for Example 2.1
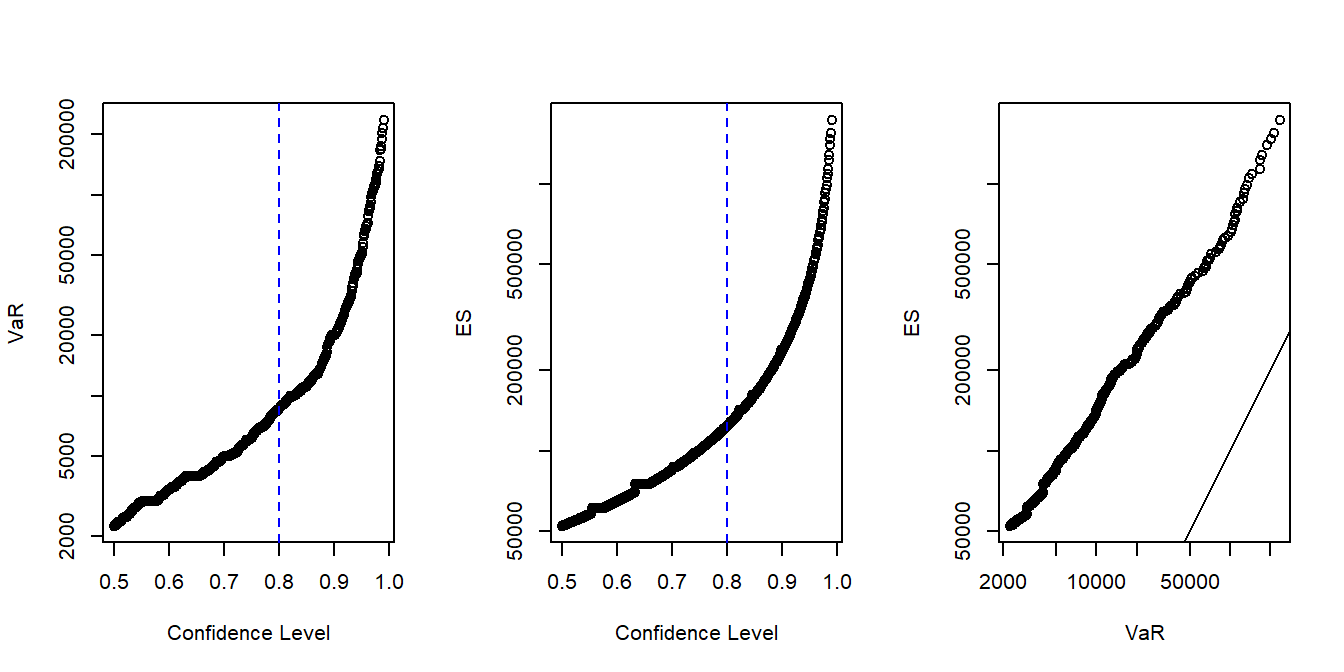
Figure 2.1: Property Fund \(VaR\) and \(ES\) Plots. The left-hand panel shows the value at risk \(VaR\) for several confidence levels and the middle panel gives similar information for the expected shortfall (\(ES\)). The confidence level \(\alpha = 0.80\) is marked with a blue dashed vertical line. Note that the vertical axes ranges differ. This is emphasized by direct comparison in the right-hand panel where the 45-degree solid line falls below the empirical values.
A risk measure that encompasses both the value at risk and the expected shortfall is the range value at risk, as presented in Embrechts, Liu, and Wang (2018). This is defined as \[\begin{equation} RVaR_{(\alpha,\beta)}(X) = \left\{ \begin{array}{cc} VaR_{\alpha}(X) & \text{if } \beta = 0 \\ \frac{1}{\beta} \int_{\alpha}^{\alpha + \beta} VaR_{a}(X) da ~~~& \text{if } 0 < \beta \le 1 - \alpha \end{array} \right. . \tag{2.4} \end{equation}\] To see the connection, first note that as \(\beta \rightarrow 0\), \(RVaR_{(\alpha,\beta)}(X) \rightarrow VaR_{\alpha}(X)\). Second, by choosing \(\beta = 1- \alpha\) and using equation (2.3), we have \(RVaR_{(\alpha,1-\alpha)}(X) =\) \(ES_{\alpha}(X)\). From this perspective, the \(VaR\), \(ES\), and \(RVaR\) can all be represented as an “average” quantile and so we refer to them as quantile-based risk measures.
Example 2.2. Property Fund and the Pareto Distribution. To show how these uncertainty measures might work with parametric distributions, we consider the Pareto distribution because it is commonly used in insurance applications. This distribution function can be expressed as \[\begin{equation} F_X(x) = 1- \left(\frac{\gamma}{x+\gamma}\right)^{\eta} , \tag{2.5} \end{equation}\] for \(x>0\), where \(\gamma\) is the scale parameter and \(\eta\) is the shape parameter. Using a Pareto distribution, the property fund data was fit using maximum likelihood. The estimated parameters turn out to be \(\hat{\gamma}_P = 2,282\) and \(\hat{\eta}_P = 0.9991\). With these parameter values, the value at risk can be estimated using the expression \[ \widehat{VaR}_{\alpha} = \hat{\gamma}_P \left[ (1- \alpha)^{-1/\hat{\eta}_P} - 1\right] . \] This gives the estimated value for \(RVaR_{(\alpha,0)}\). In addition, for \(\beta>0\), easy calculus shows that \[ \begin{array}{ll} \widehat{RVaR}_{(\alpha,\beta)}(X) &= \frac{1}{\beta} \int_{\alpha}^{\alpha + \beta} \hat{\gamma}_P \left[ (1- \gamma)^{-1/\hat{\eta_P} - 1} - 1\right] d \gamma \\ &= \frac{\hat{\gamma}_P}{\beta} \left\{ \frac{ (1- \alpha)^{1-1/\hat{\eta_P}} -(1- \alpha-\beta)^{1-1/\hat{\eta_P}}}{1-1/\hat{\eta_P}} \right\}- \hat{\gamma}_P .\\ \end{array} \]
Using a level of \(\alpha = 0.80\), Figure 2.2 summarizes the fitted value of \(RVaR\) over different values of \(\beta\). For reference, this level of \(\alpha\) yields estimated values of \(\widehat{VaR}_{0.80} =\) 9,145 and \(\widehat{ES}_{0.80} =\) 413,540. These values are marked in Figure 2.2 with the horizontal lines. They represent lower and upper values of \(RVaR\).
R Code for Example 2.2
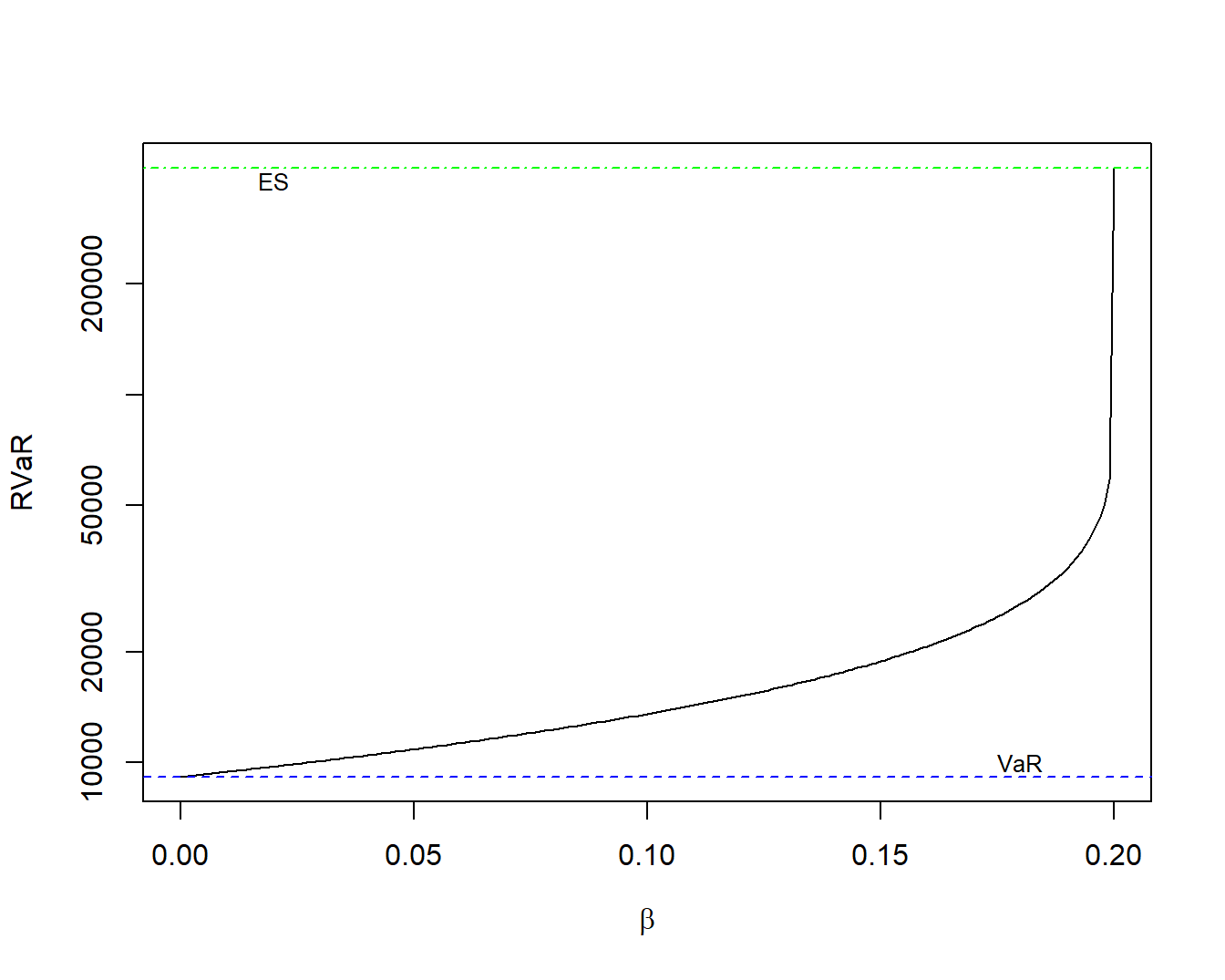
Figure 2.2: Property Fund \(RVaR\) Plot. For benchmarking, recall that \(VaR\) and \(ES\) represent lower and upper values of \(RVaR\).
Video: Section Summary
2.2 Risk Retention Function
A risk retention function is a mapping that indicates what portion of a risk is retained by the risk owner after a risk transfer is in place. For notation, let \(g(\cdot)\) denote a generic risk retention function. As in Section 1.4.1, one might use \(g(x) = \min(x,u)\) where \(u\) is the upper limit of the loss to be retained. In general, the loss retained is \(g(X)\) and the loss transferred, or ceded, is \(X-g(X)\). Both are random variables and each has their own distribution. Unless specified otherwise, you may assume that \(0 \le g(x) \le x\). The lower bound means that negative retained losses are not possible and the upper bound means that one cannot have a retained loss that exceeds the loss.
2.2.1 A Risk Retention Function
For an important special case that covers many situations of interest, consider the following expression.
Risk Retention Function \[\begin{equation} g(x; d, c, u) = \left\{ \begin{array}{cl} 0 & \text{if } x < d \\ c(x-d) & \text{if } d \le x < u \\ c(u-d) & \text{if } x \ge u \end{array} \right. . \tag{2.6} \end{equation}\]
Here, \(d\) is the deductible, \(c\) is the coinsurance amount, and \(u\) is the upper limit of coverage. This function can also be expressed as \[ g(x; d, c, u) = c \left\{(x \wedge u) - (x \wedge d) \right\} . \] The wedge symbol \(\wedge\) is used for the minimum operator and is defined as \(x \wedge z = \min(x,z)\). The variable \(X \wedge u\) is called a limited loss variable and it is often used for limited expected value calculations in actuarial contexts.
The risk retention parameters may be collected into a vector \(\boldsymbol \theta =(d, c, u)\). With this notation, one can use integration by parts and express the mean retained loss as \[\begin{equation} {\small \begin{array}{rl} \mathrm{E}[g(X;\boldsymbol \theta)] = & \displaystyle\int_d^u c(x-d) dF(x) +c(u-d)[1-F(u)] \\ = & -c(x-d) [1-F(x)] \bigg\lvert^u_d + c \displaystyle\int_d^u [1 - F(x)] dx + c(u-d)[1-F(u)] \\ = & c \displaystyle\int_d^u [1 - F(x)] dx . \end{array} \tag{2.7} } \end{equation}\] This development assumes that \(d\) is finite. Although not needed for our applications, the case of \(d= -\infty\) can also be handled in a straightforward fashion. We can also write \[ \mathrm{E}[g(X;\boldsymbol \theta)] = c \left\{ \mathrm{E}(X \wedge u) - \mathrm{E} (X \wedge d) \right\} , \] as the limited expected value expression \(\mathrm{E}(X \wedge x) = \int^x_0 [1-F(z)] dz\) is routinely tabulated in software.
Consistent with the motivating examples in Section 1.4, we use summary measures of the amount ceded, \(X-g(X)\), such as mean or a quantile, to represent the risk transfer cost (\(RTC\)) . In the baseline case of using means, we can calculate the risk transfer cost as the overall mean minus the mean retained loss, that is, \(RTC(\boldsymbol \theta) = \mathrm{E}(X) - \mathrm{E}[g(X;\boldsymbol \theta)]\).
The risk retention function introduced in equation (2.6) is motivated by insurance risk transfers and covers many applications of interest. If the risk owner is a company, one can imagine small losses being handled by a service contractor and large losses being covered by an insurer. If the risk owner is an insurance company, small losses may be the responsibility of a policyholder with large losses being covered by a reinsurer (see Chapter 4). Other interpretations are possible. Moreover, the risk retention function provides the groundwork for extensions that will be taken up in subsequent chapters covering risk exchanges among multiple parties in Section 4.5 and multiple risks in Chapter 7.
2.2.2 Distribution Function
With the vector of risk retention parameters, \(\boldsymbol \theta =(d, c, u)\), the distribution function of the retained risk \(g(X;\boldsymbol \theta)\) can be expressed as \[\begin{equation} F_{g(X; \boldsymbol \theta)}(z)= \left\{ \begin{array}{ll} F(d) & \text{if } z =0 \\ F\left(\frac{z}{c}+d\right) & \text{if } z < c(u-d)\\ 1 & \text{if } z \ge c(u-d) \end{array} \right. . \tag{2.8} \end{equation}\] There is additional discreteness due to the parameters \(d\) and \(u\). Figure 2.3 allows one to visualize the distribution function of the retained loss with discreteness induced by the insurance parameters.
R Code for Figure 2.3
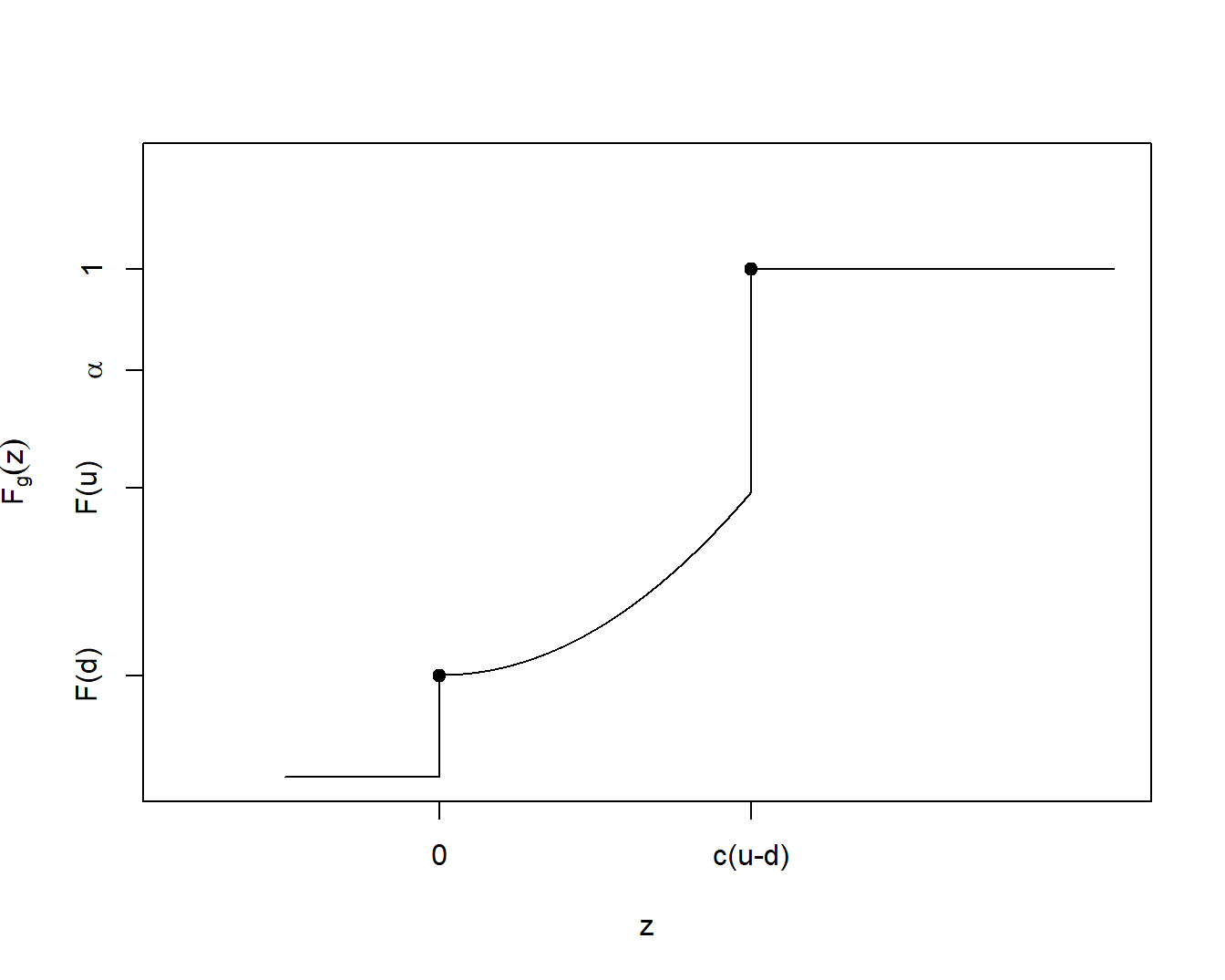
Figure 2.3: Distribution Function of Retained Risk. Even if the loss \(X\) has a continuous distribution, there can be discontinuities induced in the distribution of retained loss through the introduction of deductibles \(d\) and upper limits \(u\).
2.2.3 Risk Measures
Recall that \(F^{-1}_{\alpha}=VaR_{\alpha}(X)\) is a quantile for a random variable \(X\). Quantiles have several attractive properties. For example, they preserve location translations in the sense that \(VaR_{\alpha}(X-a_0)=VaR_{\alpha}(X)-a_0\) for a constant \(a_0\). Further, they preserve scale translations in the sense that \(VaR_{\alpha}(a_1 X)=a_1 VaR_{\alpha}(X)\) for a positive \(a_1\). Summarizing, we have \[\begin{equation} VaR_{\alpha}(a_1 X-a_0) = a_1 \ VaR_{\alpha}(X) -a_0, \ \ \ \text{for } a_1 > 0 . \tag{2.9} \end{equation}\] From this expression and equations (2.3) and (2.4), we see that the expected shortfall and the range value at risk also preserve location and scale translations.
Now use Figure 2.3 to help determine the quantile of the retained loss distribution, \(VaR_{\alpha}[g(X;\boldsymbol \theta)]\). From the figure, if \(F(d) < \alpha < F(u)\), then one finds \(VaR_{\alpha}[g(X;\boldsymbol \theta)]\) has the solution \(z\) of the equation \(\alpha = F\left(\frac{z}{c}+d\right)\). Straight-forward algebra shows this to be \(VaR_{\alpha}[g(X;\boldsymbol \theta)] = c \left( F^{-1}_{\alpha} - d\right).\) From the figure, if \(\alpha \ge F(u)\), then \(VaR_{\alpha}[g(X;\boldsymbol \theta)] = c \left( u - d\right).\) Summarizing, we have \[\begin{equation} VaR_{\alpha}[g(X;\boldsymbol \theta)] =\left\{ \begin{array}{cl} 0 & \text{if } \alpha < F(d) \\ c(F^{-1}_{\alpha}-d) & \text{if } F(d) \le \alpha < F(u) \\ c(u-d) & \text{if } F(u) \le \alpha \end{array} \right. . \tag{2.10} \end{equation}\] In the same way, we have \[\begin{equation} {\small ES_{\alpha}[g(X;\boldsymbol \theta)]=\left\{ \begin{array}{ll} \frac{c}{1-\alpha} \left\{ \mathrm{E} (X \wedge u)- \mathrm{E} (X \wedge d) \right\} & \text{if } \alpha \le F(d) \\ \frac{c}{1-\alpha} \left\{ \mathrm{E} (X \wedge u)- \mathrm{E} (X \wedge F_{\alpha}^{-1}) \right. & \text{if } F(d) \le \alpha < F(u) \\ \left. \ \ \ \ \ \ \ +(1-\alpha)(F_{\alpha}^{-1} - d) \right\} \\ c(u - d) & \text{if } F(u) \le \alpha \\ \end{array} \right. . } \tag{2.11} \end{equation}\]
\(Under~the~Hood.\) Show Development of the \(ES\)
From equations (2.10) and (2.11), we see that if \(F(u) \le \alpha\), then the value at risk and expected shortfall are the same. That is, they are equivalent for small values of upper limits, at least smaller than the \(\alpha\) quantile. This observation will be useful in Chapter 7 when interpreting risk retention frontiers.
Extending this for the range value at risk, \(RVaR\), for retained risks, one can show that \[\begin{equation} \begin{array}{ll} {\small RVaR_{(\alpha,\beta)}[g(X;\boldsymbol \theta)] }\\ {\scriptsize =\left\{ \begin{array}{ll} 0 & \alpha +\beta< F(d) \\ \frac{c}{\beta} \left\{ (1-\alpha-\beta) (d-F^{-1}_{\alpha+\beta}) \right. & \alpha < F(d) < \alpha +\beta < F(u) \\ \left. \ \ \ + [\mathrm{E} (X \wedge F^{-1}_{\alpha+\beta})- \mathrm{E} (X \wedge d)] \right\} \\ \frac{c}{\beta} \left\{ (1-\alpha-\beta) (d-u) + [\mathrm{E} (X \wedge u)- \mathrm{E} (X \wedge d)] \right\} & \alpha < F(d) < F(u) < \alpha +\beta \\ \frac{c}{\beta} \left\{ (1-\alpha)(F^{-1}_{\alpha}-u) + \beta (u -d) \right.& F(d) < \alpha < F(u) < \alpha +\beta \\ \left. \ \ \ + [\mathrm{E} (X \wedge u)- \mathrm{E} (X \wedge F^{-1}_{\alpha})] \right\} \\ \frac{c}{\beta} \left\{ (1-\alpha)(F^{-1}_{\alpha} -F^{-1}_{\alpha+\beta}) + \beta(F^{-1}_{\alpha+\beta} - d) \right.& F(d) < \alpha < \alpha +\beta < F(u) \\ \left. \ \ \ \ \ + [\mathrm{E} (X \wedge F^{-1}_{\alpha+\beta})- \mathrm{E} (X \wedge F^{-1}_{\alpha})] \right\} \\ c(u - d) & F(d) < F(u) < \alpha \\ \end{array} \right. . } \end{array} \tag{2.12} \end{equation}\]
\(Under~the~Hood.\) Show Development of the \(RVaR\)
Although complex, equations (2.11) and (2.12) show how to compute a retained risk version of the \(ES\) and \(RVaR\) using expressions involving standard limited expected value quantities.
Example 2.3. Property Fund Claims Distribution - Continued. Let us continue Example 2.1 where we examined empirical estimates of the distribution using 1,377 property damage claims. We now impose an upper limit \(u\) but, for simplicity, assume no deductible (\(d=0\)) and no coinsurance (\(c=1\)). A confidence level of \(\alpha = 0.99\) is used for this illustration. For these data, it turns out that \(\widehat{VaR}_{0.99} =\) 236,427 which is marked with blue dashed vertical lines in Figure 2.4. The left-hand panel of this figure shows a change in the slope for the \(VaR\) whereas the right-hand panel shows that the \(ES\) is smoother at this point.
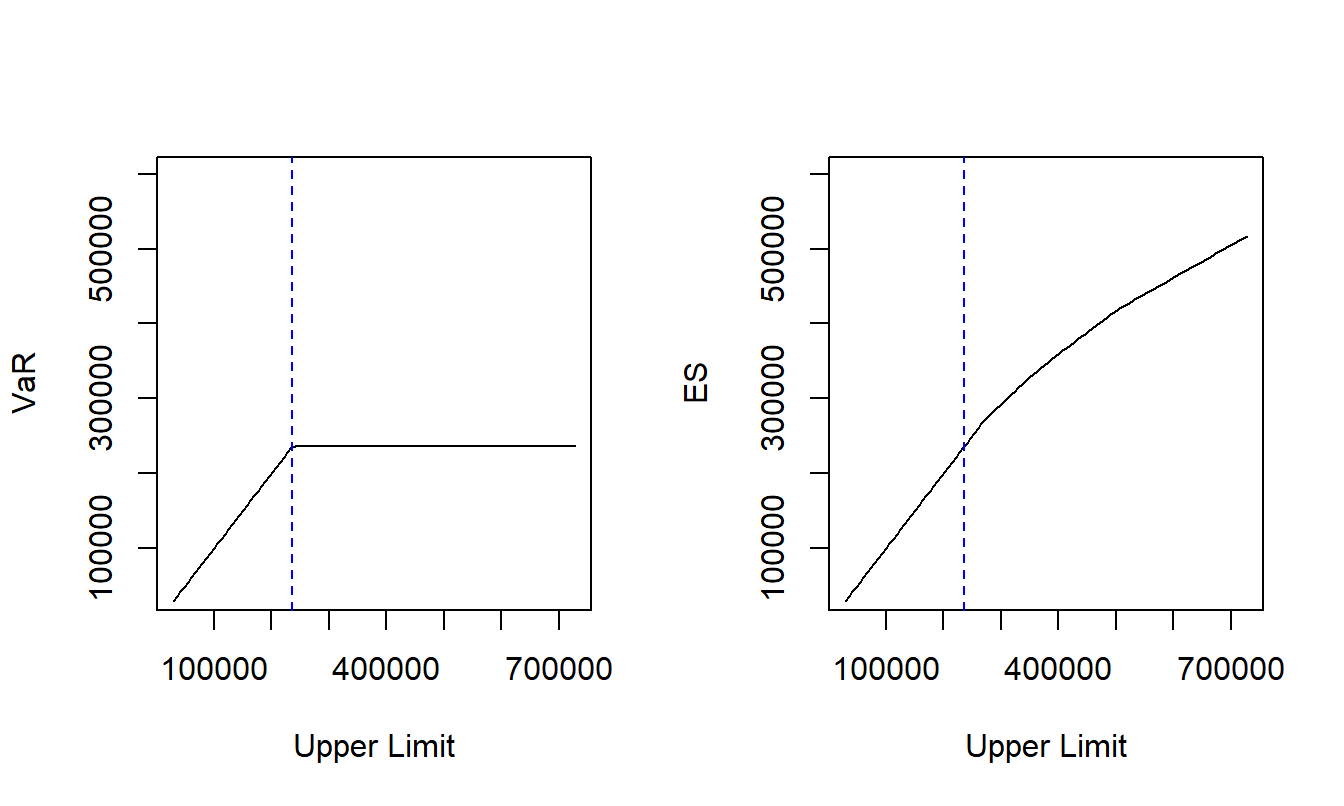
Figure 2.4: Property Fund \(VaR\) and \(ES\) Plots for Various Upper Limits. The left-hand panel shows the retained risk \(VaR\) over different upper limits and the right-hand panel gives similar information for the expected shortfall (\(ES\)). The blue dashed vertical line marks \(\widehat{VaR}_{\alpha}\).
Video: Section Summary
2.3 Risk Retention Changes
Risk managers would like to minimize both the uncertainty of retained risks and the cost of transferring risks. However, there is a natural trade-off between the risk retained, \(g(X; \boldsymbol \theta)\), and the amount transferred, \(X- g(X; \boldsymbol \theta)\). To get more insights into this trade-off, I consider a risk retention function \(g(\cdot)\) that changes only through its parameters. With these potential changes, risk managers have substantial flexibility to adjust both the level of uncertainty and costs to suit their preferences. For example, for an upper limit policy, one can let \(u\) approach zero so that no risk is retained, resulting in full transfer. Conversely, one can let \(u\) approach infinity, resulting in full retention.
Changes in risk retention parameters lead to changes in both the uncertainty of the retained risk and the associated cost of risk transfer. This section summarizes these two changes as a ratio, specifically by examining the change in the uncertainty of risk retained, the risk measure, per unit change in the risk transfer cost.
The rationale for investigating this ratio originates from the observation that risk managers possess an intuitive understanding of risk retention parameters, such as comparing two upper limits (e.g., 250,000 and 500,000). They can also readily interpret changes in risk transfer costs, as these represent firm expenditures (e.g., the cost savings associated with shifting from an upper limit of 250,000 to 500,000). Conversely, interpreting a risk measure, and changes therein, proves to be more complex. The aim is to facilitate interpretation by expressing these changes in risk measures as a “standardized unit,” per unit change in the risk transfer cost. Chapter 3 outlines alternative approaches for summarizing the trade-off between the risk transfer cost and the uncertainty of the retained risk.
2.3.1 Discrete Changes
To help with the interpretation, I begin by examining discrete changes of risk retention summary measures for a Pareto distribution which is commonly used in insurance.
Example 2.4. Changes of Risk Retention Summary Measures Using a Pareto Distribution. Assume that \(X\) follows a Pareto distribution with scale parameter \(\gamma\) and shape parameter \(\eta\), as in equation (2.5). The \(\alpha\) quantile is \[ F^{-1}_{\alpha} = \gamma \left( (1-\alpha)^{-1/\eta}-1 \right) . \] One can use this, with equation (2.10), to get the value at risk for the retained risk.
The Pareto mean turns out to be \(\mathrm{E}(X) = \frac{\gamma}{\eta-1}\) (if \(\eta>1\)). Further, from equation (2.7), the expected value of retained risks for the Pareto distribution is \[ \mathrm{E} [g(X; \boldsymbol \theta)] = \mathrm{E} [g(X; d, c, u)] =\frac{c \gamma}{\eta-1} \left[ \left(\frac{\gamma}{d+\gamma}\right)^{\eta-1} - \left(\frac{\gamma}{u+\gamma}\right)^{\eta-1} \right] . \]
This is based on standard limited expected value calculations documented in, for example, Actuarial Community (2020), Chapter 18. Limited expected values, together with equation (2.11), also allow one to get the expected shortfall for the retained risk.
For this example, I use the risk transfer cost as the expected risk minus this expected value of retained risks, \(RTC(\boldsymbol \theta) = \mathrm{E} (X) - \mathrm{E} [g(X; \boldsymbol \theta)]\). To be even more specific, I further assume that \(\eta = 3\), \(\gamma = 1000\), and \(\alpha = 0.98\). Table 2.1 illustrates the effect on risk transfer costs and risk measures for selected risk retention parameters.
| Deduct \(d\) | Coins \(c\) | Upper Limit \(u\) | \(RTC\) | \(VaR\) | \(\frac{\Delta VaR}{\Delta RTC}\) | \(ES\) | \(\frac{\Delta ES}{\Delta RTC}\) |
|---|---|---|---|---|---|---|---|
| 0 | 1.0 | Inf | 0.00 | 2684.03 | NaN | 4526.05 | NaN |
| 100 | 1.0 | Inf | 86.78 | 2584.03 | -1.15 | 4430.27 | -1.10 |
| 0 | 0.9 | Inf | 50.00 | 2415.63 | -5.37 | 4102.66 | -8.47 |
| 0 | 1.0 | 2000 | 55.56 | 2000.00 | -12.31 | 2000.00 | -45.47 |
| Note: | |||||||
As with the statistical package R conventions, Inf means ‘infinity’
|
|||||||
and NaN means ‘not a number.’
|
|||||||
| The symbol \(\Delta\) means ‘change in’. |
As a baseline, assume deductible \(d=0\), coinsurance \(c=1\), and upper limit \(u=\infty\). Then, the cost of ceding the risk is \(RTC(d=0, c=1, u=\infty) =\) 0 and the level of uncertainty is \(VaR_{\alpha=0.98}[g(X;\boldsymbol \theta)]=\) 2,684.03.
Suppose that one decides to impose a deductible \(d=100\). Then, the risk transfer cost increases to \(RTC(d=100, c=1, u=\infty) =\) 86.78. By paying 86.78, the risk owner is only responsible for losses in excess of 100 and not responsible at all for losses less than 100. With this deductible, the uncertainty level goes down to 2,584.03. This is a reduction of uncertainty level per unit change of transfer cost which turns out to be -1.15.
Table 2.1 summarizes changes for all three risk retention parameters. For this example, the upper limit option yields the greatest reduction in uncertainty level (2,684.03 -2,000.00 = 684.03) per change in transfer cost (0.00 -55.56 = -55.56) that is summarized as a ratio, -12.31.
Happily, these results are consistent with the \(ES\) measure. That is, if the manager opted to instead use the \(ES\) instead of the \(VaR\), again the upper limit option would result in the greatest reduction per risk transfer cost change. This is comforting in the sense that the manager may not have a deep intuitive appreciation for either measure yet both recommend the same action meaning that any decision about which measure to rely upon is of less importance.
R Code for Example 2.4
2.3.2 Differential Changes
Naturally, the functions that we work with are highly nonlinear and so proportional changes vary considerably according to the separation of two comparison points and their location. Moreover, discrete changes become awkward to interpret as one moves to a world of multivariate risks, which we do beginning in Chapter 4. So, I now introduce differential changes to ease the interpretation.
As motivated by Section 2.3.1 on discrete changes, we look to the ratio of differential change in the quantile per unit differential change in risk transfer costs. For simplicity, this chapter focuses on risk transfer costs using expectations so that \(RTC(\boldsymbol \theta) = \mathrm{E } (X) - \mathrm{E}[g(X; \boldsymbol \theta)]\). As overall mean losses do not change with risk retention parameters, this means that any differential of risk transfer costs is simply minus one times the differential of mean retained claims. To illustrate for the coinsurance parameter \(c\), from equation (2.10) and the discussion following equation (2.7), we have
\[ \begin{array}{lc} \frac{\partial_c~ VaR_{\alpha}[g(X;\boldsymbol \theta)] } {\partial_c~ RTC(\boldsymbol \theta)} &= \left\{ \begin{array}{cl} 0 & \text{if } \alpha < F(d) \\ -\frac{F^{-1}_{\alpha}-d}{\mathrm{E}(X \wedge u)-\mathrm{E}(X \wedge d)}& \text{if } F(d) \le \alpha < F(u) \\ -\frac{u-d}{\mathrm{E}(X \wedge u)-\mathrm{E}(X \wedge d)} & \text{if } \alpha \ge F(u) \end{array} \right. . \end{array} \]
This uses the short-hand notation \(\partial_c = \frac{\partial}{\partial c}\). Results for other parameters appear in Table 2.2.
Table 2.2. Differential Changes of Risk Transfer Cost, Value at Risk, and Expected Shortfall
\[ {\small \begin{matrix} \begin{array}{c | ccc | c} \hline \text{Summary} & & \text{Parameter} (\theta) \\ \text{Measure} & \text{Deduct } d & \text{Coins } c & \text{Upper Limit } u & \text{Range of } \alpha\\ \hline {\scriptsize \partial_{\theta}~ RTC(\boldsymbol \theta)} & c\{1-F(d)\} & -\{\mathrm{E}(X \wedge u)-\mathrm{E}(X \wedge d)\} & -c\{1-F(u)\} & \\ \hline \partial_{\theta}~ VaR_{\alpha}[g(X;\boldsymbol \theta)] & \begin{array}{cc} 0 \\ -c \\ -c \\ \end{array} & \begin{array}{cc} 0 \\ F^{-1}_{\alpha}-d \\ u -d \end{array} & \begin{array}{cc} 0 \\ 0 \\ c \\ \end{array} &\begin{array}{c} \alpha < F(d) \\ F(d) \le \alpha < F(u) \\ F(u) \le \alpha \\ \end{array} \\ \hline \partial_{\theta}~ ES_{\alpha}[g(X;\boldsymbol \theta)] & \begin{array}{c} \frac{-c}{1-\alpha}\{1-F(d)\} \\ -c \\ \\ -c \\ \end{array} & \begin{array}{c} \frac{1}{1-\alpha} \left\{ \mathrm{E} (X \wedge u)- \mathrm{E} (X \wedge d) \right\} \\ \frac{1}{1-\alpha} \left\{ \mathrm{E} (X \wedge u)- \mathrm{E} (X \wedge F_{\alpha}^{-1}) \right . \\ \left. +(1-\alpha)(F_{\alpha}^{-1} - d) \right\} \\ u - d \\ \end{array} & \begin{array}{c} \frac{c}{1-\alpha} \{1-F(u)\} \\ \frac{c}{1-\alpha} \{1-F(u)\} \\ \\ c \\ \end{array} & \begin{array}{c} \alpha < F(d) \\ F(d) \le \alpha < F(u) \\ \\ F(u) \le \alpha \\ \end{array} \\ \hline \end{array} \end{matrix} } \]
Example 2.5. Changes of Risk Retention Summary Measures Using a Pareto Distribution - Continued. This is a continuation of Example 2.4. Table 2.3 summarizes differential changes for selected risk retention parameters. From this table, one can see that:
- In the baseline case where \(d=0\), \(c=1\), and \(u=\infty\), a finite reduction in the required risk capital is produced by the coinsurance parameter \(c\).
- In the case where \(d=100\), \(c=1\), and \(u=10000\), the differential for changing the \(u\) parameter is zero. This is because at this value of \(u\), we have \(\alpha = 0.98 < F(10000)\), meaning that the upper limit is in a region where the retained risk is constant in \(u\).
- From the third and fourth rows, the largest (negative) relative change is for the parameter \(u\). That is, at these parameter values, if one were to move any of the risk retention parameters, the greatest decline in the uncertainty per unit of risk transfer cost is produced by changes in the upper limit parameter.
R Code for Table 2.3
| \(d\) | \(c\) | \(u\) | \(RTC\) | \(VaR\) | \(\frac{\partial_d VaR}{\partial_d RTC}\) | \(\frac{\partial_c VaR}{\partial_c RTC}\) | \(\frac{\partial_u VaR}{\partial_u RTC}\) |
|---|---|---|---|---|---|---|---|
| 0 | 1.0 | Inf | 0.00 | 2684.03 | -1.00 | -Inf | NaN |
| 100 | 1.0 | 10000 | 86.78 | 2584.03 | -1.33 | -28.42 | 0.00 |
| 500 | 0.9 | 2000 | 300.00 | 1965.63 | -3.37 | -3.86 | -27.00 |
| 1000 | 0.9 | 1500 | 459.50 | 450.00 | -8.00 | -0.98 | -15.62 |
Video: Section Summary
2.4 Convexity and Smoothness of Uncertainty Measures
Numerical optimization algorithms often rely heavily on concepts such as convexity and smoothness (e.g., differentiability) of functions. Figure 2.4 illustrates how different risk measures can exhibit varying degrees of smoothness. Hence, in the simple univariate case, I delineate these characteristics for the measures that summarize the distribution, specifically, the distribution function, the value at risk, and the expected shortfall.
According to the definition of convexity, a linear (convex) combination of a function evaluated at points should be greater than or equal to the function evaluated at the same linear combination of points. Specifically, a function \(h\) is convex if \(h[c u_1 + (1-c)u_2] \le c h(u_1) + (1-c)h(u_2)\) for \(0 \le c \le 1\). In other words, the line segment between any two points on the graph lies at or above the graph. In the same way, a function \(h\) is concave if \(-h\) is convex. For a concave function, the line segment between any two points on the graph lies at or below the graph. This is an abstract definition that can be applied in many contexts. As will be discussed in Section 4.4, convexity is a very useful property for numerical optimization. Because of this, our interest will be mainly in thinking about the “points” as retention parameters such as an upper limit \(u\), not the potential losses \(X\).
To visualize the convexity and smoothness, Figure 2.5 shows the distribution function, value at risk (quantile), and the expected shortfall as a function of the upper limit \(u\). In this figure, the deductible is set as \(d=0\) and the coinsurance as \(c=1\).
The left-hand panel shows the discontinuity, or jump, of the distribution function in equation (2.8). As a function of the upper limit \(u\), the distribution function is neither convex nor concave. (This is also evident in the more complex Figure 2.3.) The middle panel shows the value at risk based on equation (2.10). This function is concave in \(u\) and is also linear except at the point \(F^{-1}_{\alpha}\). At this point, there is a sharp discontinuity in the slopes, indicating a type of “non-smoothness.” The right-hand panel shows the expected shortfall based on equation (2.11). The figure suggests that the \(ES\) is also concave and is smooth in \(u\).
R Code for Figure 2.5
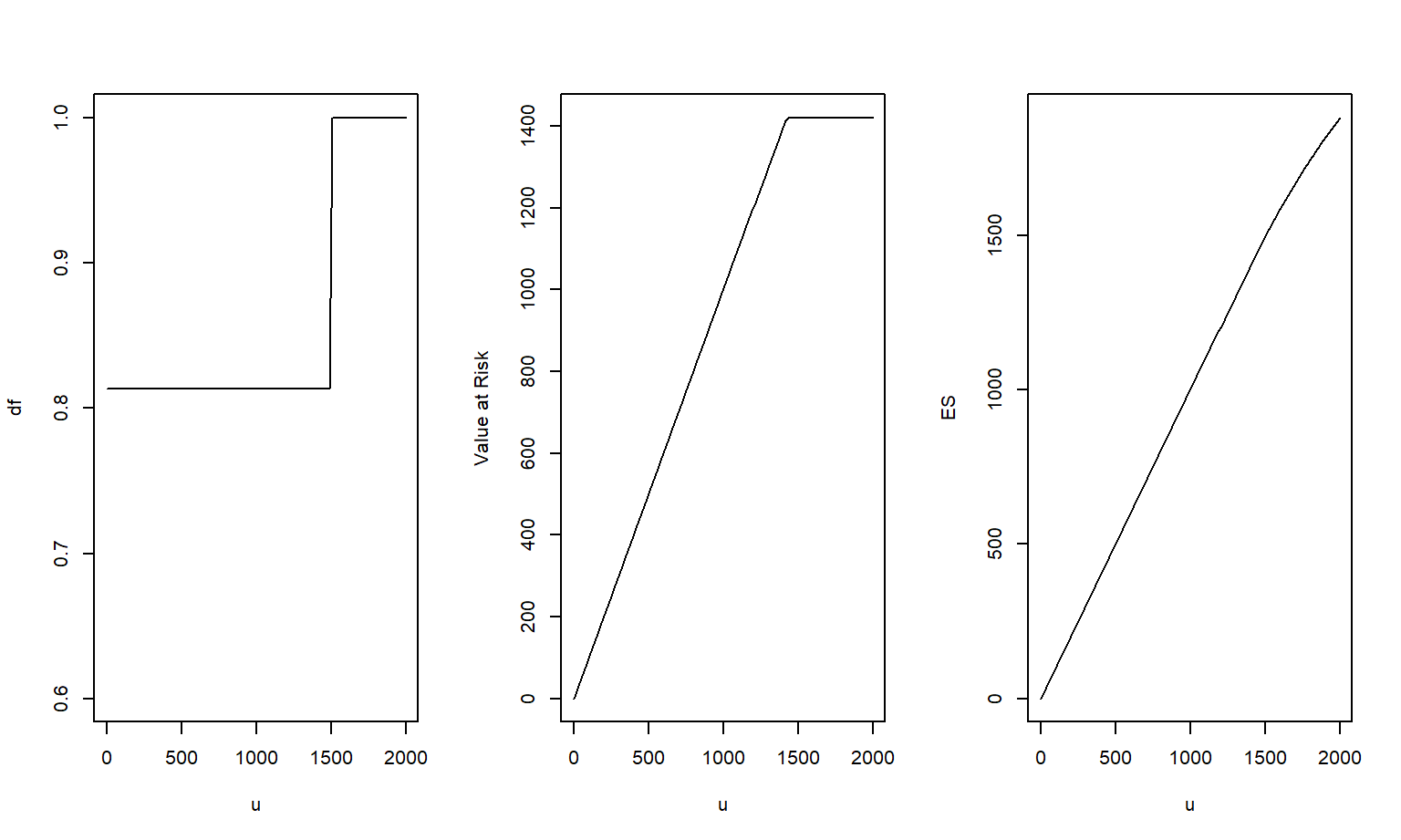
Figure 2.5: Uncertainty Measures versus Upper Limit \(u\). The measures of uncertainty are the distribution function, value at risk, and \(ES\).
Some readers will find it instructive to take differentials in \(u\) just less than and greater than \(u = F^{-1}_{\alpha}\) using equation (2.11). This gives another way to get insights into the smoothness of \(ES\) for retained risks. To explain the smoothness of the \(ES\) in \(u\), return to equation (2.11) and take a partial derivative with respect to \(u\) to get \[ {\small \partial_u ~ES_{\alpha}[g(X;\boldsymbol \theta)]=\left\{ \begin{array}{ll} \frac{c}{1-\alpha} \left\{ 1-F(u)\right\} & \text{if } \alpha < F(d) \\ \frac{c}{1-\alpha} \left\{ 1-F(u) \right\} &\text{if } F(d) \le \alpha < F(u) \\ c & \text{if } F(u) \le \alpha \\ \end{array} \right. . } \] using the relation \(\partial_u \mathrm{E} (X \wedge u) = 1-F(u)\). This expression shows that the derivative is smooth in \(u\); even at the point \(\alpha = F(u)\), it has the same derivative from the left and from the right.
Although the risk measures are typically smooth and convex (or concave) in the presence of a single retention parameter, this is not true in general with multiple parameters. This is best illustrated with a simple example.
Example 2.6. Pareto Distribution. I use the same assumptions as in Example 2.4 but with \(\gamma = 2000\) and \(\alpha =0.85\) (to better display graphically the effects we want to show). Now select two sets of retention parameters, \((d_1 =0, u_1 = 1000)\) and \((d_1 =1000, u_1 = 2500)\). Using equation (2.11), I evaluate the expected shortfall at each point and at linear combinations of the form \((d=cd_1+(1-c)d_2,u=cu_1+(1-c)u_2)\). Figure 2.6 shows the results, establishing that the expected shortfall is neither convex nor concave.
R Code for Example 2.6
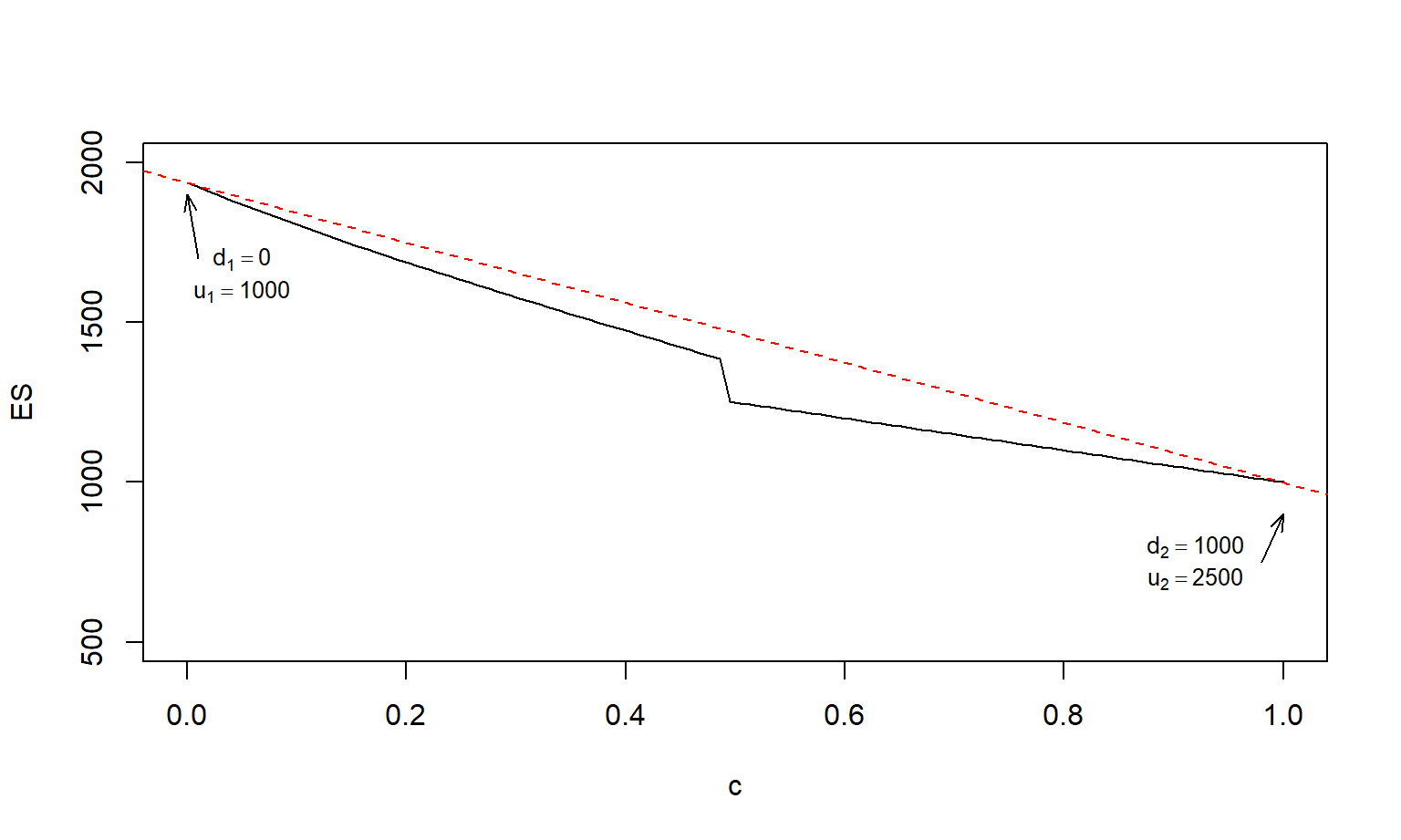
Figure 2.6: Expected Shortfalls are Neither Convex nor Concave. The solid line shows the \(ES\) evaluated at linear combinations of two points, \((d_1 =0, u_1 = 1000)\) and \((d_1 =1000, u_1 = 2500)\). The straight dashed red line shows the linear combination of the \(ES\)s evaluated at the two points.
This lack of convexity will be revisited in Section 5.1 in the context of multiple risks.
Video: Section Summary
2.5 Supplemental Materials
2.5.1 Further Resources and Readings
Readers wanting a quick refresher of some basic statistical and actuarial concepts may refer to the online book, Actuarial Community (2020). In particular, Chapter 3 describes calculation of risk transfer costs for policies with coverage modifications, Chapter 10 provides an introduction to risk measures, and Chapter 18 describes limited expected value calculations.
For example, Chapter 10 of Actuarial Community (2020) describes alternative versions of the expected shortfall \(ES\). That is, closely related to the \(ES\) are the average value at risk, also known as the tail value at risk and the conditional value at risk, among others. In fact, under mild continuity assumptions, they are all equivalent. For the purposes of this text, I assume such continuity assumptions hold and use their different alternative expressions as needed. Naturally, there are some applications where this is not the case. To understand their differences, you can begin with the distinctions drawn in Chapter 10 of Actuarial Community (2020).
As summarized in Wang and Zitikis (2021), both \(VaR\) and \(ES\) have solid axiomatic foundations and “appear in the banking regulation frameworks of Basel III/IV, as well as in the insurance regulation frameworks of Solvency II and the Swiss Solvency Test.” Thus, although their application to insurable risk portfolio problems considered in this book is novel, their usefulness in determining adequate solvency for banks and insurers suggest that they are appropriate measures upon which to base this work.
For additional discussion of the ratio of differential changes, see Frees (2017). Instead of risk transfer costs, that paper describes the differential change in a risk measure (\(RM\)) per unit change in expected retained premiums, that is, \({\small \left\{\partial_{\theta}~ RM[g(X;\boldsymbol \theta)]\right\}/\left\{\partial_{\theta}~ \mathrm{E~} g(X; \boldsymbol \theta)\right\}} =\) \({\small- \left\{\partial_{\theta}~ RM[g(X;\boldsymbol \theta)]\right\}/\left\{\partial_{\theta}~ RTC(\theta)\right\}}\), and calls this a risk measure relative marginal change, or \(RM^2\) change, for short.
2.5.2 Exercises
Section 2.1 Exercises
Exercise 2.1. Comparing Parametric Value at Risk Measures. In Example 2.1, we compared nonparametric versions of the value at risk \(VaR\) and expected shortfall \(ES\). Subsequently, in Example 2.2 we determined parametric versions of an extension, the range value at risk \(RVaR\), using the Pareto distribution. In this exercise, we compare the \(VaR\) and \(ES\) using different parametric assumptions. As a baseline, we assume the Pareto distribution with scale parameter \(\gamma = 2300\) and shape parameter \(\eta = 0.999\) (rounded from Example 2.2 for simplicity).
a. Using the R function mpareto(), verify that the mean for this distribution is infinite. This means that we cannot use the method of moments to compare distributions. (Hint: It may be convenient to use the conventions in the online book Actuarial Community (2020).)
b. One can use quantiles from the Pareto distribution to determine parameters of the gamma distribution. Specifically, the illustrative code shows how to match the 60th and 70th percentiles. Use this code to match the 20th and 80th percentiles (that results in more stable parameter estimates). This illustrative code:
\(~~\bullet~~\) Uses the R function multiroot() to find the root of several (nonlinear) equations, a function that we will use going forward.
\(~~\bullet~~\) Re-parameterizes parameters to constrain them to be positive. For each parameter, the search is over the entire real line but then the solution is transformed to the positive portion of the real line through exponentiation. This re-parameterization technique saves us from the trouble of constraining parameters.
c. Figure 2.7 is a plot that summarize a comparison of \(VaR\) measures for the Pareto and gamma distribution assumptions. Note that the gamma \(VaR\) measures are much lower than the corresponding Pareto values for large values of \(\alpha\) (confidence levels). Write code to reproduce this plot. (Hint: See the Online Supplement for illustrative code.)
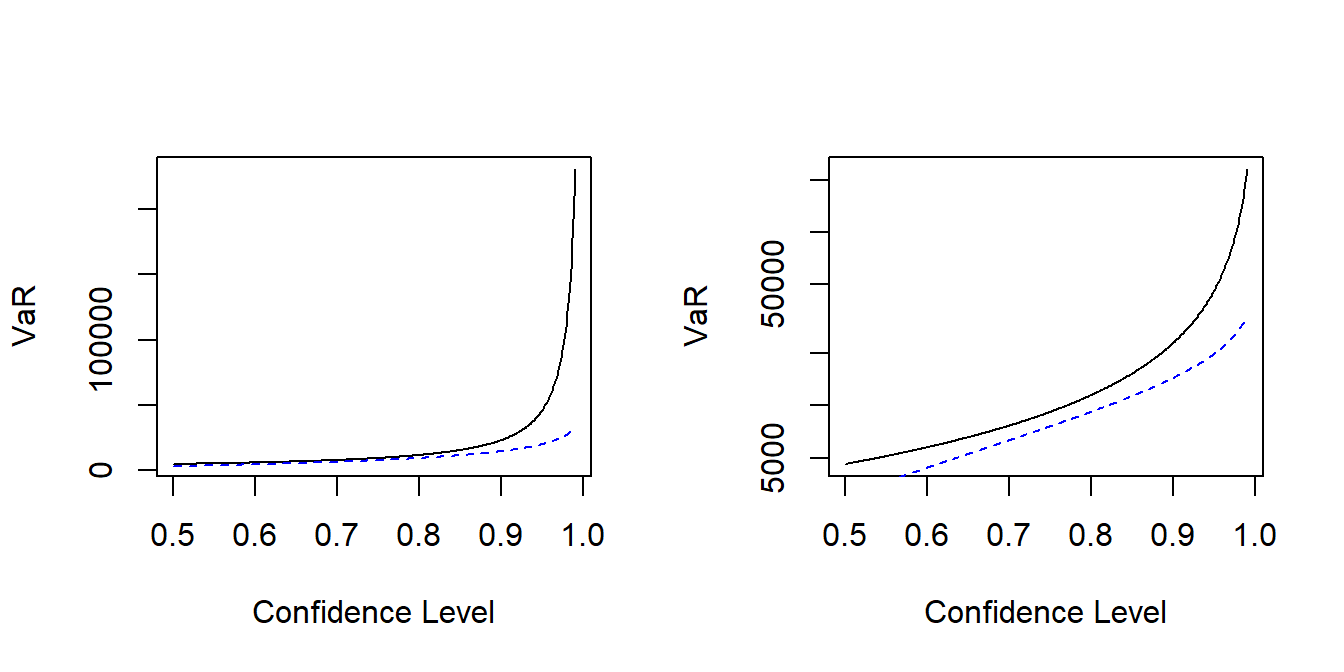
Figure 2.7: Value at Risk (\(VaR\)) for Pareto and Gamma Distributions. The black solid line is for the Pareto distribution, the blue dashed vertical line is for the gamma distribution. The left-hand panel is in the original units that emphasizes the differences in \(VaR\) for large confidence levels. The vertical axis in the right-hand panel is on the log scale that permits visualization of the differences over the range of the confidence levels.
R Code for Parameter Identification Through Matching Percentiles
Show Exercise 2.1 Solution
Exercise 2.2. Comparing Parametric \(RVaR\) Measures. In Exercise 2.1, we compared value at risk \(VaR\) measures based on different parametric distributions that were equated by the method of matching percentiles. However, we could not compare the \(ES\) risk measures because the mean of the distribution was infinite. The purpose of this exercise is to show how to make the comparison using the range value at risk \(RVaR\) measure.
Specifically, compare the Pareto and gamma distributions with the same parameters determined in Exercise 2.1. Use the R function integrate() and equation (2.4) to compute \(RVaR\) values. To check your work, it turns out that \(RVaR(\alpha = 0.80, \beta = 0.10)\) is 11,518.43 for the gamma distribution and is 13,673.63 for the Pareto distribution. Figure 2.8 provides a rough idea of other values of \(RVaR\) to calibrate your work.
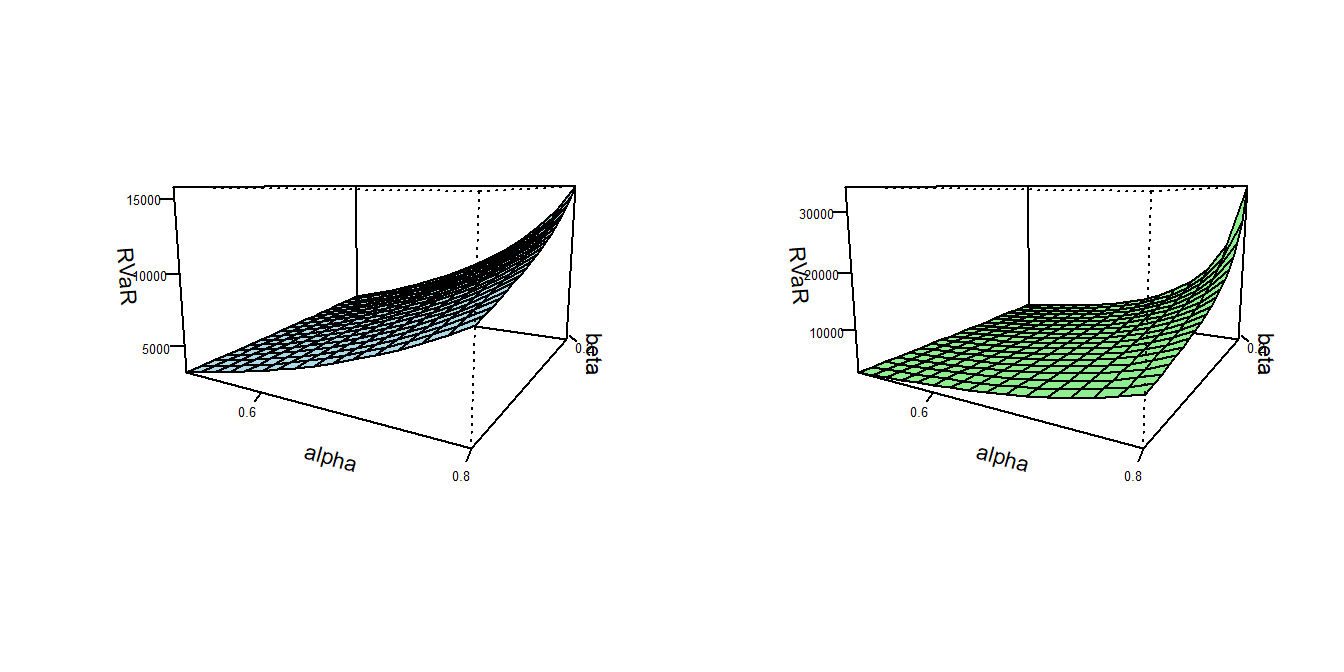
Figure 2.8: Range Value at Risk (\(RVaR\)) for Gamma and Pareto Distributions. The left-hand figure is for the gamma distribution and the right-hand is for the Pareto distribution. Values of \(RVaR\) are given by level of confidence alpha and range parameter beta.
Show Exercise 2.2 Solution
Exercise 2.3. Risk Measures for the Sum of Two Risks. Consider the following two non-identical random variables:
- \(X_1\) has a gamma distribution with shape parameter 2 and scale parameter 5,000. Thus, the mean is 10,000 and the 95th percentile is 23,719.
- \(X_2\) has a Pareto distribution with shape parameter 3 and scale parameter 2,000. Thus, the mean is 1,000 and the 95th percentile is 1,714.
Assume that the risks are independent and consider their sum \(S= X_1 + X_2\) (extensions to dependence and more than two risks begin in Chapter 4).
a. Determine \(\Pr( S \le 18000)\). Hint: Use the convolution formula \(\Pr(S \le y) =\) \(\int_0^y F_1(y-z) f_2(z) dz\) and the R function integrate().
b. Determine the 95th percentile of \(S\). Hint: Use the R function uniroot() and solve the equation \(\Pr( S \le y) = 0.95\).
c. Determine the expected shortfall of \(S\) for confidence level \(\alpha = 0.95\). Hint: Use the limited expected value expression in Display (2.3).
Show Exercise 2.3 Solution
Section 2.2 Exercises
Exercise 2.4. Risk Retention for the Sum of Two Risks. Consider the sum of two risks \(S\) introduced in Exercise 2.3 and let \(g(S) = g(S;d =100,c =0.8, u=30000)\) be the retained risk. For confidence level \(\alpha = 0.95\), determine:
a. the value at risk \(VaR_{\alpha}[g(S)]\),
b. the expected shortfall \(ES_{\alpha}[g(S)]\),
c. the range value at risk \(RVaR_{\alpha,\beta = 0.04}[g(S)]\), and
d. find the value of a newer risk measure, the \(GlueVaR\).
The \(GlueVaR\) was introduced by Belles-Sampera, Guillén, and Santolino (2014); it is a flexible risk measure and so exhibits many of the same qualities as the \(RVaR\). Based on this work, we consider the expression \[ GlueVaR = \omega_1 VaR_{\alpha} + \omega_2 ES_{\alpha} + \omega_3 ES_{\alpha+\beta} , \] where \(\omega_1\), \(\omega_2\), and \(\omega_3\) are weights lying with [0,1] that sum to one. For this exercise, use \(\beta = 0.04\) and \(\omega_1 = \omega_2 = \omega_3 = 1/3\).
Show Exercise 2.4 Solution
Exercise 2.5. Portfolio Management and Simulation. You are the Chief Risk Officer of a telecommunications firm and responsible for its captive insurer. The firm has several property and liability risks. We will consider:
- \(X_1\) - buildings, modeled using a gamma distribution with mean 200 and scale parameter 100.
- \(X_2\) - motor vehicles, modeled using a gamma distribution with mean 400 and scale parameter 200.
- \(X_3\) - directors and executive officers risk, modeled using a Pareto distribution with mean 1000 and scale parameter 1000.
- \(X_4\) - cyber risks, modeled using a Pareto distribution with mean 1000 and scale parameter 2000.
Denote the total risk as \(S = X_1 + X_2 + X_3 + X_4\). You have negotiated to transfer risks in excess of \(d = 100\), to an upper limit of \(u=5000\), yet covering only \(c=0.80\) of those claims. That is, the risk transferred is \(g(S)=g(S;d=100,c=0.80,u=5000)\) where \(g()\) is defined in equation (2.6). Using simulation techniques, you should:
a. Plot the simulated distribution of \(g(S)\).
b. Determine the expected value and standard deviation of \(g(S)\).
c. Determine the value at risk \(VaR\) at confidence levels \(\alpha = 0.80, 0.90, 0.95\).
d. Determine the expected shortfall \(ES\) at confidence levels \(\alpha = 0.80, 0.90, 0.95\).
For readers wanting a refresher in simulation techniques, see the online book Actuarial Community (2020), Chapter 6.
Show Exercise 2.5 Solution
Section 2.3 Exercise
Exercise 2.6. Risk Retention Changes for the Sum of Two Risks. This is a continuation of Exercises 2.3 and 2.4. We now seek to observe how the various risk measures change as retention parameters \(d,c,u\) change. For simplicity, we restrict attention to the basic measures, value at risk and expected shortfall. Further, from the discussion in Section 2.2.3, it is clear that the effects of the coinsurance parameter are linear. So, although the changes to this parameter can have important financial implications, because of the linearity they are easy to anticipate and so we do not need to investigate them further here.
a. Quantify the impact of an increase of 500 to the deductible \(d\) for both the \(VaR\) and \(ES\) measures using the baseline scenario in Exercise 2.5. Compare this to an increase of 500 in the upper limit \(u\). For each risk measure, describe the size and direction of the changes.
b. Quantify the impact of increases 10, 50, 100, and 500 to the deductible \(d\) for both the \(VaR\) and \(ES\) measures where the increase is measured from the baseline scenario in Exercise 2.5. Note the change in each risk measure per unit change in the deductible.
c. Use the results summarized in Table 2.2 to calculate the differential change at the baseline scenario in each risk measure for a change in deductible \(d\). Compare this change to the discrete changes in part (b). You should establish that the differential approximations are much easier to compute and are excellent proxies for the discrete changes in the cases considered.
Show Exercise 2.6 Solution
2.5.3 Appendix. Distortion Risk Measures
Risk measures are well known to actuaries and other insurance analysts as they are employed in solvency regimes that base capital adequacy criteria on standard risk measures such as \(VaR\) and \(ES\). In this book, I use risk measures to inform readers about insurance retention and portfolio applications. The choice of the risk measure matters.
The focus of this book is on selected commonly used risk measures introduced in this chapter, the \(VaR\), \(ES\), and \(RVaR\). However, given their importance in practice, it is not surprising that there is a robust literature on alternative risk measures. The following describes one class that encompasses many (but not all) of these alternatives. For actuaries and other analysts that provide advice on insurable risk portfolios, it is helpful to understand how these alternatives are defined and where one can look if further investigation into alternatives seem warranted
Using notation from Serfling (1980) (page 265), a general risk measure can be expressed as: \[\begin{equation} RM(F) = \int_0^1 F^{-1}(t) ~dK(t) = \int_0^1 J(t) F^{-1}(t) dt + \sum_{j=1}^m a_j F^{-1}(\alpha_j) . \tag{2.13} \end{equation}\]
This is known as a distortion risk measure and encompasses many important measures as special cases, cf. Assa (2015).
- We have already considered the \(VaR\) (quantile) risk measure where one chooses \(J(t)\equiv 0\), \(m=1\), and \(a_1=1\).
- The expected value is also a special case of \(RM(F)\) by using \(J(t)\equiv 1\) and \(m=0\).
- The expected shortfall \(ES\) is another special case, where one chooses \(m=0\) and \(J(t)= 0\) for \(0 \le t < \alpha\) and \(J(t)= 1/(1-\alpha)\) for \(\alpha \le t \le 1\). Here, \(\alpha\) (\(0 \le \alpha <1\)) is the risk preference level.
- The risk measure from the proportional hazards transform arises when \(m=0\) and \(J(t)= \alpha(1-t)^{\alpha-1}\). Here, \(0 < \alpha \le 1\).
Further, from Embrechts, Liu, and Wang (2018) (Appendix, EC.1), we have that \(RVaR\) is a special case of the distortion measure with the choice of \[ J(t) = \left\{ \begin{array}{cl} \min[(I(t>\alpha)\frac{t-\alpha}{\beta},1] & \text{if } \beta>0 \\ I(t>\alpha) & \text{if } \beta = 0 \\ \end{array} . \right. \]