Chapter 12 The Role of Dependence in Managing Insurable Risks
Chapter Preview. Managers of risk portfolios understand that dependence among risks can be critical when making decisions to manage those risks. In extreme cases where all risks in a portfolio are strongly related, such as due to earthquake and flood events, opportunities for risk sharing and diversification benefits are limited. More broadly, dependence influences decisions to take on risks, how much risk to retain, the pricing of risks, and even whether a private marketplace for insurance is available.
The chapter begins with Section 12.1 which describes the ubiquity of dependence when considering insurable risks. To provide guidance in assessing its impact, the section categorizes dependence based on the number of risks and whether one should focus on small (“local”) versus broad (“global”) impacts of dependence.
Following a brief discussion on approaches for assessing broad impacts of dependence, Section 12.2 emphasizes local impacts by introducing a tool called portfolio expectation dependence sensitivity. Building on sensitivity work done in prior chapters, this tool enables analysts to assess the impact of small changes in dependence.
With the structure developed in the first two sections, Section 12.3 describes the impact of dependence on small collection of risks that this chapter calls a portfolio. Specifically, the discussion addresses the impact on risk transfer costs, the uncertainty of a portfolio, and the risk retention parameters obtained when constructing an optimal insurable risk portfolio.
Section 12.4 continues with a discussion for a large collection of risks that this chapter calls a pool. In modeling pools of many entities with several risks, it is common to allow for dependencies among different risk types yet assuming independence among entities. However, these commonly used assumptions may not be a sensible approximation to reality. In particular, risk managers are concerned with effects of contagion, where there is an association or spread of loss from one entity to another within a portfolio. Contagion can be most naturally interpreted in the context of a natural disaster or other catastrophic event common to many entities within the portfolio. Contagion can eradicate any benefits achieved from pooling, and this section provides approaches for assessing effects of contagion.
12.1 Role of Dependence
As we learned in Chapter 6, managing insurable risks begins with identifying and mitigating important risks, determining which are insurable or partially insurable, and introducing risk controls and prevention techniques to mitigate their frequency and severity. Despite extensive efforts to control and prevent undesirable outcomes, risk owners will still have a portfolio of risks with a financial impact that can be managed by risk transference, the subject of this book. But what is the role of dependence among risks?
Dependence is common among insurable risks. Any risk owner, whether a person, corporation, or an insurer, responsible for several insurable risks can expect dependency among them. For example, a person’s unobserved attitude towards risk has a common influence on outcomes of automobile, liability, and health risks. For a corporation, management’s approach towards undertaking risky projects, personnel and their training in mitigating risky outcomes, as well as common geographical influences, all suggest that risky outcomes can depend upon one another in unforeseen ways. For an insurer, overall market conditions, the corporate philosophy for underwriting standards, and the industries in which they underwrite risks have common latent effects on all risks, inducing dependencies. Dependence is the norm when considering insurable risks, not the exception. Beginning with the Chapter 4 introduction of multiple (multivariate) risks, this book immediately introduced a structure to allow for dependence in a flexible manner - the copula. Any framework designed to manage insurable risks portfolios needs to incorporate a dependency structure at its foundations.
Dependency, whether weak, strong, or extreme, is a common feature of collections of insurable risks. This chapter argues that dependency is critical for insurable risk management for some purposes. Nonetheless, as will be seen, other business decisions are relatively robust to the effects of dependency. Dependency can be difficult to quantify and so it worthwhile to understand which business decisions critically rely upon dependence and which are relatively robust to its effects.
Portfolio versus Pool. When the number of risks is large, even small dependencies among risks can lead to a breakdown in the usual asymptotic results such as the law of large numbers. Inspired by these mathematical results, it is useful to think about situations in which the number of insurable risks can be categorized as “small” versus “large.” This chapter refers to a small collection of risks as a portfolio and a large number of risks as a pool. For instance, a portfolio could consist of 2, 6, or 15 risks, as seen in previous examples in this book, and a pool is for a larger number of risks, typically in the hundreds, thousands, or more. Admittedly, this distinction is vague and there is a continuum over this size measure, but this categorization will help us appreciate potential impacts of dependency in different scenarios.
Local versus Global. Another distinction to be made when discussing dependency is whether the impact is “local” or “global.” In some instances, the extent of dependence is well understood either from empirical evidence or knowledge of the situation. In these cases, local measures that quantify the impact of small changes in dependence are useful. Sensitivities for general auxiliary variables have already been introduced, and this framework will be applied to dependence parameters in this chapter. Conversely, in other situations, the extent of dependence is not well understood. More global assessment is needed in these instances, informing risk managers of the best and worst likely outcomes over a range of dependencies.
Why is dependency difficult to measure? In part this is because of this meaning of the word “dependency” in insurance risk modeling. Managers not accustomed to the subtleties of stochastic modeling think about one variable affecting another as a type of dependency. In contrast, for an insurance analyst, an observed variable affecting an outcome can be thought of as a regression-type effect which is relatively straight-forward to model using standard tools. That is, an observed variable, sometimes known as a covariate, can be used to “explain” another variable in a regression setting. Dependency modeling is something more; after known covariate effects have been accounted for in the model, “dependencies” measure other relationships not present in known observable covariates. That is, dependencies account for latent, unobserved, relationships that persist.
Despite the well-appreciated effects of dependence in insurance practice, the scope of quantitative tools for assessing the impact of dependence has been limited in the actuarial and insurance literature. This is especially surprising given its prominence in finance, a closely related field that also deals with financial risks. As just one example, students of finance learn about the capital asset pricing model (CAPM) that employs the covariance between a stock and a market index. Historically, finance has profitably used basic tools such as covariance and regression to explain relationships because of the linearity among risk types. In contrast, insurance risk applications typically deal with highly non-linear relationships meaning that these basic tools are less helpful.
Another reason for the lack of development of insurance risk management tools for assessing dependency is that dependence is typically not a decision variable representing an action that a portfolio manager might take. A portfolio manager might choose the upper limit of a risk, whether to take on a risk, or set a price to take on a risk. Each of these actions may be influenced by dependencies but a portfolio manager cannot, for example, set the correlation of a risk within a portfolio to be negative (although this could be desirable for diversification purposes).
Some Motivating Examples. Before presenting some general results, let us first examine two examples where it can be helpful to understand the impact of dependence.
Example 12.1. Reinsurance Expected Payments. Suppose that \(X_1\) represents a general liability claim and \(X_2\) represents expenses associated with the claims. Specifically, this is known as an allocated loss adjustment expense (ALEA), a type of insurance company expense that is attributable to the settlement of individual claims such as lawyers’ fees and claims investigation expenses. In Frees and Valdez (1998), a sample of 1,500 claims and expenses from then Insurance Services Office (now Verisk Analytics) were used to calibrate a joint distribution with Pareto marginal distributions for claims and expenses. Fitting a normal copula model, it turns out that the fitted association parameter is 0.473.
In addition, Frees and Valdez (1998) calculated a reinsurer’s expected payment as \(\mathrm{E} \{\min(X_1,10000) + X_2 \times[1-5000/\min(X_1,10000)] \}\). With the fitted normal copula and Pareto marginals, this turns out to be 8,183. Actuarial analysts are quite comfortable fitting distributions, such as Pareto, to marginal risks. Yet, how sensitive is this result to the dependence between claims and expenses? Techniques to be introduced in this chapter show that for every one percent change (increase) in the dependence, one expects the reinsurance premium to increase by 19. Put another way, a one percent increase in the dependence leads to a 19 / 8183 = 0.0023 proportional change in expected payments. This is a relatively small proportional change, suggesting that this expected payment is robust to dependence effects.
Show Code to Develop Reinsurance Expected Payments
Example 12.2. Value at Risk for an Insurance Portfolio. We consider a portfolio of Wisconsin Property Fund analyzed in Section 8.1.3. Recall that there are \(p=6\) lines of business, building and contents (BC), contractor’s equipment (known as “inland marine”, IM, for historical reasons), and four types of commercial auto. For simplicity, this example looks to a portfolio before any risk transference. The interest is in quantifying the value at risk (at the 98 % level) for a portfolio of 1,098 policyholders in a held-out dataset.
As described in Frees, Lee, and Yang (2016), a longitudinal/panel data set allows one to calibrate the joint distribution. For this example, we use Tweedie marginal distributions and a normal copula among the six lines. Because of covariate information, each policyholder has a different distribution. This example assumes independence among policyholders yet allow for dependence among lines of business (in Section 12.4, this assumption will be weakened). To be specific, Table 12.1 shows the dependence parameters estimated from the longitudinal/panel dataset. To emphasize, these dependence parameters summarize associations among lines after having removed (via the Tweedie regressions) the effects of covariates (such as exposures) that may induce dependencies.
| BC | IM | PN | PO | CN | CO | |
|---|---|---|---|---|---|---|
| BC | 1.000 | 0.210 | 0.276 | 0.359 | 0.265 | 0.417 |
| IM | 0.210 | 1.000 | 0.362 | 0.410 | 0.266 | 0.358 |
| PN | 0.276 | 0.362 | 1.000 | 0.552 | 0.553 | 0.490 |
| PO | 0.359 | 0.410 | 0.552 | 1.000 | 0.329 | 0.564 |
| CN | 0.265 | 0.266 | 0.553 | 0.329 | 1.000 | 0.533 |
| CO | 0.417 | 0.358 | 0.490 | 0.564 | 0.533 | 1.000 |
Figure 12.1 shows the distribution of outcomes based on 2,000 simulations of the portfolio. Because of the number of independent policyholders, it is not surprising that the distribution of the portfolio is approximately normal due to the Central Limit Theorem even though individual risks are very non-normal and non-identical. The value at risk turns out to be 29,293, in thousands.
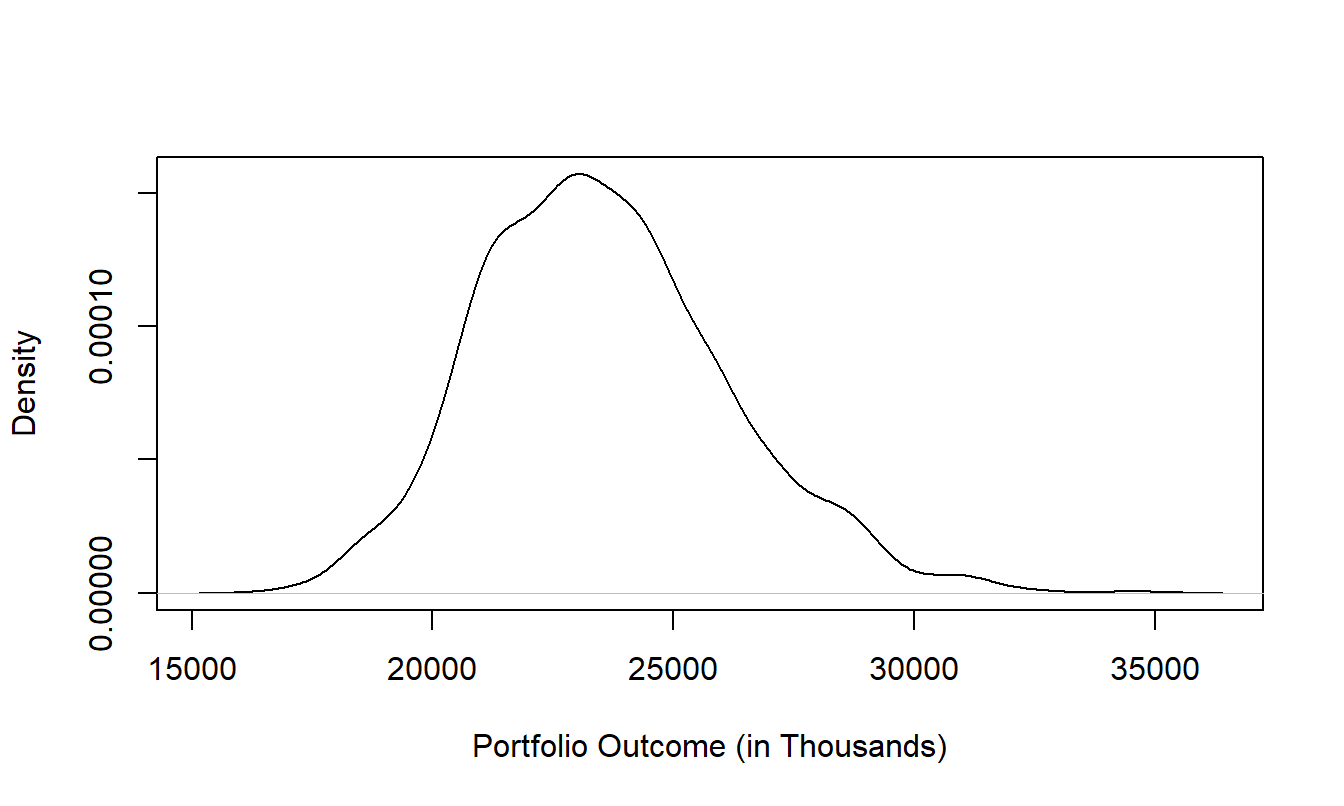
Figure 12.1: Simulated Portfolio Distribution
How sensitive is this value at risk to the dependence parameters? Using the techniques in this chapter, results shows that a one percent increase in the dependence between BC and IM, from 0.21 to 0.22, induces a decrease in the value at risk by 25.94, in thousands. On the one hand, this change is small relative to the total value at risk for the portfolio, 29,293. On the other hand, this is only one of 15 dependence parameters in Table 12.1 that concerns the portfolio manager.
12.2 Measuring Global and Local Impacts
12.2.1 Measuring Global Impact
Because dependence can be difficult to quantify, it is useful in some applications to provide a global assessment of the best and worst likely outcomes over a range of dependencies. For the worst most likely outcome, we have already utilized the concept of comonotonicity among risks, discussed in Section 9.1, that can be interpreted as perfect (positive) dependence. As also discussed in that section, the concept of the best most likely outcome in a multivariate setting is elusive, as perfect negative dependence can be vague for more than \(p=2\) risks. A model of independence among risks serves as a useful proxy for the best most likely outcome. Although it is possible to have scenarios even more favorable than independence, this is an approximation that most risk managers would gladly accept. As described in Section 9.1, a mixture model between these two bookend scenarios is a useful approach for quantifying the global impact of dependencies.
In the special case of investment portfolios, Section 9.4.2 introduced a special type of robustness where analysts aim to maximize penalized worst-case portfolio returns. The introduction in Section 9.4.2 focused on uncertainty sets for mean parameters over which one considers worst-case scenarios. In principle, this approach could be extended to insurable risks looking at uncertainty sets for dependence. Robustness has found favor among analysts in portfolio analysis; it may be that one day researchers will develop comparable tools for applications with insurable risk portfolios.
12.2.2 Measuring Local Impact
When dependencies are reasonably well understood, analysts require local measures that quantify the impact of small changes in dependence. For small changes, this book has featured a differential approach termed sensitivities. We learned how to determine risk retention sensitivities in Section 5.3 for the important cases of the value at risk and expected shortfall. In that investigation, consideration was limited to partial derivatives with respect to risk retention variables. This section shows how to use the same approach for dependencies, subject to the requisite smoothness assumptions needed for differentiation.
Additionally, sensitivities in the more complex setting of portfolio optimization were calculated in Chapter 9. There, a generic auxiliary variable a was introduced, which might represent a level of confidence \(\alpha\) or maximal risk transfer cost \(RTC_{max}\). Further, in Chapter 10, a was even used to represent a parameter associated with a marginal distribution, such as the scale. In this chapter, the auxiliary variable is a dependence parameter.
12.2.3 Portfolio Expectation Dependence Sensitivity
This section provides a tool for calibrating the sensitivity of dependence in measures of interest in actuarial and insurance applications. Here, “measures of interest” include premiums and risk measures such as value at risk and expected shortfall.
Specifically, recall that for a collection of risks, \(\boldsymbol \Sigma\) represents a matrix of association parameters, and let \(\sigma\) be a generic element from this matrix. Further, let \(h(\cdot)\) represent some summary measure of all the risks in the portfolio. It may be a risk transfer function or some other function, such as reinsurance expected payments in Example 12.1. This section shows how to compute the partial derivative \(\partial_{\sigma} \mathrm{E}[h({\bf X})]\), referred to here as a portfolio expectation dependence sensitivity.
Why is this tool useful? Because of their complexity, baseline portfolio expectations and risk measures are typically determined via simulation for a given dependence matrix \(\boldsymbol \Sigma\). Using a “brute force” method, one would repeat this over several variations of \(\boldsymbol \Sigma\) to obtain a numerical approximation of the sensitivities. In many complex situations of interest, this approach is computationally prohibitive. This section provides an alternative approach for a large class of dependence models, elliptical copulas.
Portfolio Expectation Dependence Sensitivity. To promote interpretation, the main body provides results for the Gaussian (normal) copula. In the Appendix Section 14.2, results are extended to general elliptical copulas.
Based on a Gaussian copula, the portfolio expectation dependence sensitivity can be written as \[\begin{equation} \partial_{\sigma} \mathrm{E}[h(\mathbf{X})] = \frac{1}{2} \mathrm{Cov}\left[ h(\mathbf{X}), ~W_{\sigma}(\mathbf{X})\right] , \tag{12.1} \end{equation}\] where \(\mathrm{Cov}[\cdot,\cdot]\) is the usual covariance operator. Further, define the weights \[\begin{equation} W_{\sigma}(\mathbf{X})= {\bf ns}^{\prime} ~\boldsymbol \Sigma^{-1} (\partial_{\sigma} \boldsymbol \Sigma) \boldsymbol \Sigma^{-1} ~{\bf ns} , \tag{12.2} \end{equation}\] where \({\bf ns}^{\prime} = (\Phi^{-1}[V_1], \ldots, \Phi^{-1}[V_p])\) and \((V_1, \ldots, V_p)\) is a vector of uniform random numbers that has the same copula as \((X_1, \ldots, X_p)\). Here, \(\Phi^{-1}[V]\) is simply a normal score associated with each outcome. As described further in Appendix Section 14.2, in the case where distribution of outcomes are continuous (as in the following Example 12.3), one may simply use \(F_j(X_j)\) for \(V_j\). However, for other instances with outcomes that have jumps (such as Example 12.2), resorting to more basic uniform numbers is needed. The weights in equation (12.2) appear complex but can readily be computed via simulation. To see this, consider the following example.
Example 12.3. Reinsurance Expected Payments. This is a continuation of Example 12.1. To illustrate, consider a reinsurer’s expected payment on a policy with limit \(u\) and insurer’s retention \(d\). Then, assuming a pro-rata sharing of expenses, we have \[ h(X_1,X_2) = \left\{\begin{array}{cl} 0 & \text{if } X_1 < d\\ X_1 - d + \frac{X_1 - d}{X_1}X_2 & \text{if } d \le X_1 < u\\ u - d + \frac{u - d}{u}X_2 & \text{if } X_1 \ge u .\\ \end{array} \right. \]
R Code for Example 12.3
Table 12.2 shows the maximum likelihood estimates of the fitted distribution, both under the joint copula model and assuming independence of losses and expenses.
Maximum likelihood estimates can be used to determine reinsurance expected payments, as in Table 12.3. Here, the rows are for different upper limits (\(u\)) and the columns are for different deductibles as a fraction of the upper limit (\(d/u\)). Table 12.4 gives the corresponding simulation standard errors, suggesting that using five million simulations used here is adequate for our purposes.
| Estimate | Std Error | Univariate Estimate | Univariate Std Error | |
|---|---|---|---|---|
| Loss shape | 1.1882 | 0.0699 | 1.1349 | 0.066 |
| Loss scale | 15.5303 | 1.4895 | 14.4433 | 1.3865 |
| ALAE shape | 2.376 | 0.1873 | 2.3524 | 0.1957 |
| ALAE scale | 16.5625 | 1.7649 | 15.8936 | 1.789 |
| Dependence | 0.4734 | 0.0192 | NA | NA |
|
Limit (\(u\))
|
Retention per Limit (\(d/u\))
|
||||
|---|---|---|---|---|---|
| 0.0 | 0.25 | 0.50 | 0.75 | 0.95 | |
| 10,000 | 19401 | 13137 | 8183 | 3876 | 747 |
| 100,000 | 37984 | 16124 | 8244 | 3446 | 617 |
| 500,000 | 51863 | 13046 | 6213 | 2510 | 440 |
| 1,000,000 | 57005 | 11497 | 5427 | 2175 | 380 |
|
Limit (\(u\))
|
Retention per Limit (\(d/u\))
|
||||
|---|---|---|---|---|---|
| 0.0 | 0.25 | 0.50 | 0.75 | 0.95 | |
| 10,000 | 13 | 10 | 7 | 3 | 1 |
| 100,000 | 21 | 16 | 10 | 5 | 1 |
| 500,000 | 42 | 28 | 17 | 8 | 2 |
| 1,000,000 | 57 | 37 | 22 | 10 | 2 |
Table 12.5 gives estimates of the dependence sensitivities. These measure how much the reinsurance expected payments change per a one percent change in the association parameter, e.g., moving from 0.4734 to 0.4834. Table 12.6 gives the corresponding information but as a proportion to the reinsurance expected payments. From this table, we see that a one percent change in the association parameter means less than a one percent change in reinsurance expected payments for all levels of limits \(u\) and retention \(d\). These results, and the follow-up investigation outlined in Exercise 12.5, suggest that the dependence plays a minor role in this example. In contrast, several examples are given in Dong, Frees, and Huang (2022) where dependence plays an important role.
|
Limit (\(u\))
|
Retention per Limit (\(d/u\))
|
||||
|---|---|---|---|---|---|
| 0.0 | 0.25 | 0.50 | 0.75 | 0.95 | |
| 10,000 | 0.48 | 21.25 | 18.97 | 10.81 | 2.30 |
| 100,000 | 0.80 | 43.45 | 26.77 | 12.42 | 2.37 |
| 500,000 | 1.16 | 24.79 | 12.44 | 5.24 | 0.96 |
| 1,000,000 | 1.88 | 17.03 | 8.45 | 3.75 | 0.71 |
|
Limit (\(u\))
|
Retention per Limit (\(d/u\))
|
||||
|---|---|---|---|---|---|
| 0.0 | 0.25 | 0.50 | 0.75 | 0.95 | |
| 10,000 | 0 | 0.0016 | 0.0023 | 0.0028 | 0.0031 |
| 100,000 | 0 | 0.0027 | 0.0032 | 0.0036 | 0.0039 |
| 500,000 | 0 | 0.0019 | 0.0020 | 0.0021 | 0.0022 |
| 1,000,000 | 0 | 0.0015 | 0.0016 | 0.0017 | 0.0019 |
12.3 Managing Portfolios
The impact of dependence varies according to the modeling purpose or, put another way, the type of business decision. This section focuses on three types of decisions associated with collections of insurable risks: (i) questions of risk transfer costs, (ii) quantifying overall portfolio uncertainty, and (iii) determining optimal risk retention parameters. As considerations differ by the number of risks, this section focuses on collections with a smaller number of risks, referred to here as a portfolio.
12.3.1 Risk Transfer Costs
When modeling collections of risks for pricing purposes or understanding appropriate risk transfer costs, issues of dependence are generally not at the forefront. For instance, when persons or corporations are risk owners, there are often many potential parties willing to take on a risk. A lack of coordination can be expected when different parties take on different risks, or even when different units within the same risk-taking firm are responsible for different risks. For example, a risk manager for a large corporation may purchase general and products liability, medical malpractice, and workers’ compensation, all from different vendors. For purposes of determining risk transfer costs to the corporation, prices of different risks can be treated as unrelated and independent from one another.
For another instance, consider an insurer pricing a portfolio of risks for a firm or corporation. Suppose that \(X_1, \ldots, X_p\) represents different risks and \(S = X_1 + \cdots + X_p\) represents the portfolio sum. Technical pricing often starts with a representation such as \(\mathrm{E}(S) = \mathrm{E}(X_1) + \cdots + \mathrm{E}(X_p)\); that is, the expectation of the sum is the sum of expectations. This mathematical relationship holds regardless of the dependence and reduces the pricing of a complex multivariate portfolio to the pricing of each marginal risk. Before prices are determined, insurers will rescale technical prices through adjustments based on their own portfolio of risks as well as market conditions, cf. Mildenhall and Major (2022). Dependence does come into play into these adjustments and can be important in many situations.
Naturally, there are situations when dependence affects the determination of technical prices. Example 12.1 illustrated one such situation.
12.3.2 Portfolio Uncertainty
Unlike the case for risk transfer costs, dependencies typically have a major impact on metrics that quantify portfolio uncertainty. For example, consider the case of \(p=2\) risks, \(X_1\) and \(X_2\), that form the portfolio \(S = X_1 + X_2\). In an extreme case, where \(X_1 = - X_2\) is known as counter-monotonic, we have \(S=0\) resulting in no uncertainty. Another extreme case, where \(X_1 = X_2\) that we have already identified as comonotonic, results in no diversification benefits when forming a portfolio. These are situations where even small changes in dependence are likely to be important to risk managers.
More generally, consider a collection of \(p\) risks \(\mathbf{X}\) whose dependence can be expressed in terms of a matrix of dependence parameters \(\boldsymbol \Sigma\). From the multivariate set of risks, one forms a portfolio \(h({\bf X})=h({\bf X};\boldsymbol \theta)\). Note that the risk retention parameters in \(\boldsymbol \theta\) are dropped, as we will not be optimizing over these variables in this subsection. Now consider several cases of \(RM({\bf X})\), a risk measure associated with \(h({\bf X})\). The interest here is in computing the partial derivative \(\partial_{\sigma} RM({\bf X})\).
Value at Risk Dependence Sensitivity
Risk retention sensitivities for the important cases of value at risk and expected shortfall were covered in Section 5.3. This framework can also be applied to dependence sensitivities. Specifically, let \(F\) be the distribution function associated with the random variable \(h(\mathbf{X})\). Consider only functions \(h\) so that the distribution function is smooth (differentiable) in potential outcomes and in a dependence parameter.
The quantile, or value at risk, is \(F^{-1}(\alpha; \boldsymbol \Sigma) = VaR(\boldsymbol \Sigma)=VaR\) at confidence level \(\alpha\). This forms the basis of a value at risk dependence sensitivity, \[\begin{equation} \partial_{\sigma} ~VaR(\boldsymbol \Sigma)= - \frac{F_{\sigma}[VaR; \boldsymbol \Sigma]}{F_y[VaR ; \boldsymbol \Sigma ]} . \tag{12.3} \end{equation}\] This style of calculation was previously seen in Section 5.3, equation (5.5), in the context of risk retention parameters \(\boldsymbol \theta\). A short review of this calculation is provided to appreciate the smoothness requirements.
\(Under~the~Hood.\) Show Development of the Quantile Dependence Sensitivity
As described in the prior section, many measures of interest in actuarial applications can be expressed as an expectation of a portfolio function. Moreover, this result can readily be utilized when considering quantiles. For problems of interest, evaluating the value at risk \(VaR\) and the density function \(F_y(\cdot)\) are typically straightforward using basic simulation techniques. The difficult term is \(F_{\sigma}(\cdot)\).
For the portfolio distribution function, we can consider \(I [h(\mathbf{X}) \le y]\) for some argument \(y\). With this, the expected portfolio function \(\mathrm{E}\{I [h(\mathbf{X}) \le y]\}\) \(= \Pr[h(\mathbf{X}) \le y] = F(y)\) is a distribution function. Taking a partial derivative of each side yields \(\partial_{\sigma} \mathrm{E}\{I [h(\mathbf{X}) \le y]\} =\) \(\partial_{\sigma} F(y) = F_{\sigma}(y)\), for a given value of \(y\). From equation (12.1), we know how to compute this as a portfolio expectation dependence sensitivity, which is \[\begin{equation} F_{\sigma}(y) = \frac{1}{2} ~ \mathrm{Cov}\left\{ I[h(\mathbf{X}) \le y], ~ W_{\sigma}(\mathbf{X}) \right\} , \\ \tag{12.4} \end{equation}\] where the weight \(W_{\sigma}(\mathbf{X})\) is defined in equation (12.2).
As with the portfolio expectation dependence sensitivity in equation (12.1), using equation (12.4) to determine the value at risk sensitivity appears complex but can readily be computed via simulation.
Example 12.4. Value at Risk for an Insurance Portfolio (Continued). Using the structure from Example 12.2, Table 12.7 provides the value at risk dependence sensitivities, \(\partial_{\sigma} ~VaR\). Here, there are 15 sensitivities, one for each parameter in Table 12.1. For example, a 1% increase in the association parameter between the \(BC\) and \(IM\) lines imply a decrease of 26 in the value at risk. To assess the magnitude of these sensitivities, Table 12.8 provides the same information but as a proportion of the value at risk, \((\partial_{\sigma} ~VaR)/VaR\). The results are not surprising. Small changes in dependence among risks within a portfolio imply only small changes in the value at risk.
R Code for Example 12.4 Dependence Sensitivity
| BC | IM | PN | PO | CN | CO | |
|---|---|---|---|---|---|---|
| BC | 0 | -26 | 2 | 51 | 3 | 33 |
| IM | -26 | 0 | 39 | 52 | 31 | -55 |
| PN | 2 | 39 | 0 | 40 | 84 | -25 |
| PO | 51 | 52 | 40 | 0 | -9 | 52 |
| CN | 3 | 31 | 84 | -9 | 0 | 25 |
| CO | 33 | -55 | -25 | 52 | 25 | 0 |
| BC | IM | PN | PO | CN | CO | |
|---|---|---|---|---|---|---|
| BC | 0.000 | -0.001 | 0.000 | 0.002 | 0.000 | 0.001 |
| IM | -0.001 | 0.000 | 0.001 | 0.002 | 0.001 | -0.002 |
| PN | 0.000 | 0.001 | 0.000 | 0.001 | 0.003 | -0.001 |
| PO | 0.002 | 0.002 | 0.001 | 0.000 | 0.000 | 0.002 |
| CN | 0.000 | 0.001 | 0.003 | 0.000 | 0.000 | 0.001 |
| CO | 0.001 | -0.002 | -0.001 | 0.002 | 0.001 | 0.000 |
\(Under~the~Hood.\) Technical Note on the Computation of Weights
ES and other Quantile-Based Risk Measure Dependence Sensitivity
The expected shortfall parameter sensitivity follows in the same fashion. Assuming smoothness in potential outcomes and the dependence parameter, one can modify the risk retention sensitivity from equation (5.7) to write \[\begin{equation} \begin{array}{ll} \partial_{\sigma} ~ES[h(\mathbf{X})] &=\frac{1}{1-\alpha} \left\{\partial_{\sigma}\mathrm{E}[h(\mathbf{X})] -\left.\partial_{\sigma} \mathrm{E}[h(\mathbf{X}) \wedge y]\right|_{y=VaR}\right\} \\ &\ \ \ \ \ \ \ \ + [1 - \frac{1}{1-\alpha} \{1-F[VaR]\}] \times \partial_{\sigma} VaR. \end{array} \tag{12.5} \end{equation}\] Computing the risk measure dependence sensitivities in equations (12.3) and (12.5) can be difficult. To underscore this difficulty, Exercise 12.2 shows the calculations by restricting considerations to \(p=2\) risks.
It is not difficult to extend this approach to general quantile-based risk measures. To be specific, let us consider the range value at risk introduced in Section 2.1. Recall from equation (2.4) that this is defined as \[ RVaR_{(\alpha,\beta)} = \left\{ \begin{array}{cl} F^{-1}(\alpha) & \text{if } \beta = 0 \\ \frac{1}{\beta} \int_{\alpha}^{\alpha + \beta} F^{-1}(a) ~da ~~~~& \text{if } 0< \beta \le 1- \alpha. \end{array} \right. \] In the case \(\beta = 1 - \alpha\), the \(RVaR\) reduces to the expected shortfall.
This yields the derivative of the range value at risk, another type of dependence sensitivity, \[\begin{equation} \partial_{\sigma} ~RVaR_{(\alpha,\beta)} = \left\{ \begin{array}{cl} \partial_{\sigma}F^{-1}(\alpha) & \text{if } \beta = 0 \\ \frac{-1}{\beta} \int^{F^{-1}(\alpha+\beta)}_{F^{-1}(\alpha)} F_{\sigma}(z) ~dz & \text{if } 0<\beta \le 1-\alpha ,\\ \end{array} \right. \tag{12.6} \end{equation}\] with \(\partial_{\sigma}F^{-1}(\alpha)\) given in equation (12.3).
\(Under~the~Hood.\) Show Development of the \(RVaR\) Sensitivity
Example 12.5. Expected Shortfall for an Insurance Portfolio. This is a continuation of Example 12.4. Take \(\beta = 1 - \alpha\), so that \(RVaR\) becomes \(ES\). To evaluate \(\partial_{\sigma}ES\), use equations (12.4) and (12.6) to establish \[ \partial_{\sigma}~ES = \frac{1}{2(1 - \alpha)} \mathrm{Cov}\left( W_{\sigma}(\mathbf{X}), \left\{ [h(\mathbf{X})-F^{-1}(\alpha)] ~I[ h(\mathbf{X}) > F^{-1}(\alpha) ] \right\} \right). \] This form is easy to compute using simulation.
\(Under~the~Hood.\) Development of Expected Shortfall Sensitivity
Table 12.9 provides the expected shortfall dependence sensitivities, \(\partial_{\sigma} ~ES\), and Table 12.10 provides the same information but as a proportion of the expected shortfall, \((\partial_{\sigma} ~ES)/ES\). The results are not surprising. Consistent with what we saw for the value at risk in Example 12.4, small changes in dependence among risks in a portfolio imply only small changes in the expected shortfall.
R Code for Example 12.5 Dependence Sensitivity
| BC | IM | PN | PO | CN | CO | |
|---|---|---|---|---|---|---|
| BC | 0 | -30 | 26 | 80 | -5 | 98 |
| IM | -30 | 0 | 60 | 75 | 34 | -91 |
| PN | 26 | 60 | 0 | 119 | 118 | -1 |
| PO | 80 | 75 | 119 | 0 | 12 | 116 |
| CN | -5 | 34 | 118 | 12 | 0 | 28 |
| CO | 98 | -91 | -1 | 116 | 28 | 0 |
| BC | IM | PN | PO | CN | CO | |
|---|---|---|---|---|---|---|
| BC | 0.000 | -0.001 | 0.001 | 0.003 | 0.000 | 0.003 |
| IM | -0.001 | 0.000 | 0.002 | 0.002 | 0.001 | -0.003 |
| PN | 0.001 | 0.002 | 0.000 | 0.004 | 0.004 | 0.000 |
| PO | 0.003 | 0.002 | 0.004 | 0.000 | 0.000 | 0.004 |
| CN | 0.000 | 0.001 | 0.004 | 0.000 | 0.000 | 0.001 |
| CO | 0.003 | -0.003 | 0.000 | 0.004 | 0.001 | 0.000 |
12.3.3 Constructing Insurable Risk Portfolios
Based on what has been learned so far, when modeling collections of risks for the purpose of constructing insurable risk portfolios, issues of dependence do not appear to be at the forefront.
From a global perspective, Section 9.1 introduced the mixture approach that investigated optimal portfolio construction over a wide range of dependencies. At the optimum, levels of retained risk uncertainty varied as anticipated, with strongly dependent risks exhibiting high levels of uncertainty compared with lesser dependencies. However, the optimal retention parameters were relatively stable. As the retention parameters represent decision variables of interest to risk managers, this suggests that optimal insurable risk portfolios are robust to the effects of dependence.
Also from the global perspective, there is little information about applications of distributionally robust techniques introduced in Section 9.4. Hopefully, future research will shed more light on this approach.
From the local perspective, we saw how, for special cases of linear quota share and asset investment problems, one could compute closed-form expressions for dependence sensitivities in Exercises 9.11 and 9.12. These results were expressed for general insurable risk portfolio problems through the Section 9.2 Envelope Theorem and the Section 10.1 Perturbation Sensitivity Proposition. Specifically, one can use \(a = \sigma\) for the auxiliary variable to apply these results.
With the portfolio expectation dependence sensitivity and results from Appendix Section 10.5.3, derivatives of these quantities with respect to association parameters can be evaluated as \[ \begin{array}{ll} \partial_{\sigma} ~\partial_{z_0}~ES1(z_0,\boldsymbol \theta) & =\frac{1}{2(1-\alpha)} ~\mathrm{E}_R\left\{~W_{\sigma}(\mathbf{X}) K\left(\frac{z_0-g({\bf X}; \boldsymbol \theta)}{b}\right) \right\} \\ & ~~~~- \frac{1}{2(1-\alpha)} \text{tr}( \boldsymbol \Sigma^{-1} \partial_{\sigma}\boldsymbol \Sigma)~\mathrm{E}_R\left\{ K\left(\frac{z_0-g({\bf X}; \boldsymbol \theta)}{b}\right) \right\} \\ \end{array} \] \[ \begin{array}{ll} \partial_{\sigma} ~\partial_{\boldsymbol \theta}~ES1(z_0,\boldsymbol \theta) & = \frac{1}{2(1-\alpha)} ~\mathrm{E}_R\left\{~W_{\sigma}(\mathbf{X})\left[1-K\left(\frac{z_0-g({\bf X}; \boldsymbol \theta)}{b}\right) \right] \partial_{\boldsymbol \theta} g({\bf X}; \boldsymbol \theta) \right\} .\\ & ~~~~- \frac{1}{2(1-\alpha)} \text{tr}( \boldsymbol \Sigma^{-1} \partial_{\sigma}\boldsymbol \Sigma)~\mathrm{E}_R\left\{\left[1-K\left(\frac{z_0-g({\bf X}; \boldsymbol \theta)}{b}\right) \right] \partial_{\boldsymbol \theta} g({\bf X}; \boldsymbol \theta) \right\} .\\ \end{array} \]
Example 12.6. Property Fund Portfolio. This is a continuation from Examples 10.4 and 10.5. Here, we examine perturbation sensitivities due to changes in the association, or dependency, parameters.
For a change of 0.01 in the association parameter, Table 12.11 shows the change in each decision variable at the optimum. For example, a 0.01 increase in the first dependence parameter \(\rho_{12} \approx -0.11\) leads to a 0.91 increase in the optimal value of \(VaR\), a 0.28 decrease in the optimal value of \(\theta_1\), and so forth. Changes in the association parameters have only a small impact on the optimal values of the decision variables.
| Dep Param | \(\rho_{12}\) | \(\rho_{13}\) | \(\rho_{14}\) | \(\rho_{15}\) | \(\rho_{16}\) | \(\rho_{23}\) | \(\rho_{24}\) | \(\rho_{25}\) |
| \(VaR\) | 0.91 | 0.54 | 0.8 | 0.4 | 0.36 | 0.32 | 0.66 | 0.18 |
| \(\theta_1\) | -0.28 | -0.06 | -0.05 | -0.16 | 0.04 | 0.1 | 0.16 | 0.07 |
| \(\theta_2\) | -0.83 | 0.12 | 0.2 | 0.06 | 0.14 | -0.21 | -0.22 | -0.3 |
| \(\theta_3\) | 0.19 | -0.52 | 0.21 | 0.07 | 0.09 | -0.35 | 0.21 | 0.06 |
| \(\theta_4\) | 0.38 | 0.25 | -0.47 | 0.14 | 0.16 | 0.23 | -0.38 | 0.15 |
| \(\theta_5\) | 0.1 | 0.09 | 0.15 | -0.52 | 0.08 | 0.05 | 0.12 | -0.33 |
| \(\theta_6\) | 0.24 | 0.11 | 0.17 | 0.09 | -0.41 | 0.09 | 0.17 | 0.06 |
| Dep Est | 0.06 | 0.02 | 0.05 | 0.1 | 0.17 | 0.08 | 0.15 | 0.11 |
| Dep Param | \(\rho_{26}\) | \(\rho_{34}\) | \(\rho_{35}\) | \(\rho_{36}\) | \(\rho_{45}\) | \(\rho_{46}\) | \(\rho_{56}\) | |
| \(VaR\) | 0.17 | 0.41 | 0.11 | 0.11 | 0.22 | 0.25 | 0.08 | |
| \(\theta_1\) | 0.11 | 0.11 | 0.07 | 0.07 | 0.1 | 0.11 | 0.06 | |
| \(\theta_2\) | -0.06 | 0.16 | 0.04 | 0.08 | 0.13 | 0.12 | 0.05 | |
| \(\theta_3\) | 0.08 | -0.21 | -0.2 | -0.09 | 0.09 | 0.08 | 0.04 | |
| \(\theta_4\) | 0.15 | -0.16 | 0.09 | 0.09 | -0.26 | -0.07 | 0.07 | |
| \(\theta_5\) | 0.05 | 0.08 | -0.13 | 0.04 | -0.18 | 0.06 | -0.06 | |
| \(\theta_6\) | -0.31 | 0.09 | 0.04 | -0.15 | 0.07 | -0.19 | -0.17 | |
| Dep Est | 0.09 | 0.43 | 0.46 | 0.18 | 0.4 | 0.35 | 0.4 | |
| Note: Sensitivities are per 0.01 change in association parameters. |
12.4 Managing Pools
When the number of risks in a collection is large, dependencies among risks, or inter-dependencies, can affect everything. From a minimalist perspective, this can be seen simply by looking to probability theory where basic results hinge on the extent of dependence. For instance, Stout (1974) describes mild dependency conditions where the law of large number continues to hold. Another fundamental source, Billingsley (2013), describes central limit theorems that hold even in the presence of certain types of mild dependencies. However, these basic results can fail to hold in the presence of different types of stronger dependencies.
To illustrate, consider an extreme example of a perfectly dependent pool of risks such that \(X_1 = \cdots = X_n\). In this case, the average pool risk exactly equals any one of the risks, say \(X_1\); it does not converge to the mean of the distribution as typically seen in a law of large numbers. This failure holds regardless of the risk distribution, whether it is long-tailed, standard normal, or any other distribution. When the number of risks is large, the effects of dependence are very important.
12.4.1 Effects of Contagion
It is common to think of dependencies among risks in a pool as stemming from the effects of contagion. This term likely originated from early models of infectious diseases. How can such important inter-dependencies arise?
Models of Infectious Disease. Actuarial models of contagion can be traced back to the work of Daniel Bernoulli in 1760. As described in Daw (1979), Bernoulli developed a model for the infectious disease smallpox. His work can be considered a precursor to the multi-decrement models that actuaries use to account for additional mortality effects of perils such as those due to infectious diseases such as smallpox, cholera, influenza, and so forth.
This development has led to the use of time-dependent Markov chain transition models in life and disability insurance (see, for example, Haberman and Pitacco (2018)). Such models enable analysts not only to examine additional effects but also to track the progression of infectious diseases as they spread among population segments. These models are essential for understanding and managing pandemic risks, including the AIDs epidemic of the 1980s and the more recent COVID-19 pandemic. In insurance, the term pandemic risk refers to the potential financial losses caused by a widespread disease outbreak. Insurers use transition models to predict the spread of diseases and their potential impact on claims.
Cyber Risks. Additionally, the term contagion is used within insurance to model dependencies among cyber risks. Like other perils, firms purchase insurance to shield themselves from potential financial losses resulting from digital security breaches, known as a cyber risk. These incidents can disrupt business operations, damage data, and expose sensitive information, leading to a various costs for businesses. Much like infectious diseases that affect people, cyber mishaps can spread contagiously through networks. See Eling and Schnell (2016) for a discussion of models and strategies relevant to understanding cyber risk for cyber insurance.
Catastrophes and Climate Change. Models of contagion are also used to quantify the impact on risks arising from catastrophes and climate change, as discussed in Toumi and Restell (2014). Natural disasters such as hurricanes, floods, and earthquakes can exhibit contagion effects, where a single disastrous event can simultaneously affect many different people, firms, and their properties within a geographic region. Due to contractual relationships, insurers naturally view different individuals and firms as separate risks. Additionally, different perils or coverages are often treated separately, partly due to historical reasons and partly due to differing risk distributions. For instance, as discussed in preceding chapters, a firm may have property, business interruption, motor vehicle coverage, and more. A single event, such as an earthquake, may simultaneously affect all coverages for a firm and many comparable firms within close proximity. Thus, models of contagion need to consider dependence both among individual risks and among different types of coverages.
In addition, one event can trigger or exacerbate others. That is, a disaster, such as an earthquake, can lead to secondary events, such as fires or tsunamis, affecting multiple policies. For example, the 1906 San Francisco earthquake led to widespread fires. Climate change may have even broader impacts that extend well beyond a specific geographic region. For instance, climate events can lead to widespread crop failures, critical for agriculture insurance.
The effects of contagion can be so extreme that private market insurance is not viable. For instance, if everyone in a village is subject to the same flood risk, who has resources to help rebuild in the event of a flood? With an extreme lack of diversification, risk-sharing among individual risks fails, and government intervention is required. Thus, it is common to have government-sponsored programs to provide insurance for earthquakes and floods. We are also witnessing the precarious marketplace for homeowners’ insurance in some hurricane-prone regions such as the state of Florida.
Financial Contagion and Systemic Risk. Markets may not exist or, when they do exist, exhibit frailty because economic agents do not operate in isolation but are connected by various economic relationships. This interconnectedness allows shocks to propagate throughout a financial system.
This potential for the propagation of shocks is referred to as financial contagion. Simply put, financial contagion describes a situation where the failure of one financial institution, such as a bank, could lead to a cascade of failures across the financial system. For instance, with the global financial crisis of 2008, the concept of financial contagion became central as the collapse of major financial institutions and the housing market affected global financial systems. Note, however, that the phrase “financial contagion” can mean different things to different people; for example, Pericoli and Sbracia (2003) provide five different definitions of “contagion.”
Closely related to financial contagion is the notion of systemic risk. According to J. David Cummins and Weiss (2014):
Systemic risk is the risk that an event will trigger a loss of economic value or confidence in a substantial segment of the financial system that is serious enough to have significant adverse effects on the real economy with a high probability.
Implementing this definition, Cummins and Weiss did not consider events such as the U.S. liability crisis of the 1980s and Hurricane Andrew in 1992 to be systemic events, although the financial crisis that gripped world markets in 2007-2010 was considered systemic. The criterion they applied was whether or not the event instigated sufficient adverse effects on real economic activity.
In other words, systemic risk refers to the risk of collapse of an entire financial system or market, as opposed to financial contagion, which may describe the risk associated with any one individual entity, group, or component. It is the risk that a shock will trigger severe instability or collapse in the financial system, leading to a significant economic downturn.
Models of financial contagion and systemic risks differ from the first three categories discussed: models of infectious disease, cyber risks, and catastrophes and climate change. They are similar in that they utilize models of contagions and interdependencies. However, models of financial contagion and systemic risks are different in that they typically concern relationships among financial institutions, including banks, insurers, and investment firms. In contrast, the first three categories are primarily focused on individual risks, such as individuals and firms, entities that could be considered to be policyholders of insurance companies.
12.4.2 Simulation Models of Contagion
Because of their economic impact, it is not surprising that deep and complex models of contagion have developed for each of the categories described in the previous subsection: (i) models of infectious disease, (ii) cyber risks, and (iii) catastrophes and climate change, and (iv) financial contagion and systemic risks. These models are based on knowledge of biology and demography, climatology and geology, as well as economic rules governing behavior of agents. These models are intricate, require substantial training and time to implement, and yet are capable of not only predicting the prevalence of contagious effects but also forecasting their propagation through a system. Government agencies, insurers, and other financial institutions rightfully invest substantial resources into developing such models of contagion due to their economic importance.
Linear Latent Variable Modeling. Nonetheless, there can be instances when an analyst wishes to incorporate effects of dependence but does not yet wish to commit substantial time and resources in doing so. In this scenario, it is common to use latent effect variables to induce dependencies using simulation techniques. Essentially, a latent variable is an unobserved variable that, in this instance, is common to several risks. Because it is common to several risks, it induces a (positive) dependence. For example, suppose that \(X_1^*, X_2^*\) represent two (unobserved) risks and that the latent \(\alpha\) represents a third variable that is also unobserved. Then, one might observe the outcomes: \[ \begin{array}{ll} X_1 =X_1^* + \alpha \\ X_2 =X_2^* + \alpha .\\ \end{array} \tag{12.7} \] Even when the underlying variables \(X_1^*, X_2^*,\) and \(\alpha\) are independent, the observed versions \(X_1\) and \(X_2\) are dependent due to the common latent variable \(\alpha\).
An important advantage of the structure in Display (12.7) is that it is easy to generate using simulation techniques. One simply generates (typically independently) \(X_1^*, X_2^*, \alpha\) and then combines them according to Display (12.7) to get dependent outcomes \(X_1\) and \(X_2\). Historically, this method has been used with normally distributed outcomes, so that if \(\{X_1^*, X_2^*, \alpha\}\) are jointly normal, then so are \(\{X_1, X_2\}\). However, for our purposes, other distributions are needed and this preservation of marginal distributions is not maintained. For example, if one starts with a Pareto distributed risk \(X_1^*\), then the resulting \(X_1\) will not have a Pareto distribution when perturbed by a random latent variable \(\alpha\). Therefore, another approach is more suitable for our purposes.
Latent Variable Modeling of Dependencies Approach. For a specific example, suppose that we wish to generate dependent variables \(\{X_1, X_2\}\), where \(X_1\) has a medium-tail gamma distribution and \(X_2\) has a long-tail Pareto distribution, and they are joined by a Gaussian copula. As seen in Section 7.1, for each replicate \(r=1, \ldots, R\):
- Create a realization of dependent bivariate uniform random variates \(\{V_{1r}, V_{2r}\}\).
- Create a realization of dependent bivariate losses \(\{X_{1r}, X_{2r}\}\), for example by using the inverse of each distribution function, \(X_{jr} = F_j^{-1}(V_{jr})\), \(j= 1, 2\).
Let us focus on the first step, creating dependent bivariate uniform random variates. In practice, this can be done readily via, for example, the R package copula using the function rCopula, Hofert et al. (2018). To see how to do this using a latent variable modeling of dependencies, start with independent uniform random variates \(\{V_{1r}^*, V_{2r}^*\}\). Next, convert them to independent standard normal random variables through the transform \(\epsilon_{jr}^* = \Phi^{-1}(V_{jr}^*)\) for \(j=1,2\). Now, let \(\alpha_r\) be normal random variable independent of \(\{\epsilon_{1r}^*, \epsilon_{2r}^*\}\), and define
\[
V_{jr} = \Phi \left(
\frac{\epsilon_{jr}^* + \alpha_r}{\sqrt{1 + \sigma^2_{\alpha}}}
\right), ~~~ j=1,2.
\]
That is, assuming that \(\alpha\) has mean zero and variance \(\sigma^2_{\alpha}\), then \(y_{jr}^* =\epsilon_{jr}^* + \alpha_r\) is a normally distributed random variable with mean zero and variance \(1 + \sigma^2_{\alpha}\). Thus, the quantity inside the parens is simply a standard normal random variable and the standard normal distribution function \(\Phi(\cdot)\) converts it to a uniform random variable. The variables \(\{V_{1r}, V_{2r}\}\) are dependent because they share the common latent variable \(\alpha\). One can show that the amount of dependence is controlled by the uncertainty of the latent variable through the parameter \(\sigma^2_{\alpha}\).
Dependence Modeling for Pools. We now extend this approach to pools. The portfolios discussed in this book have focused on collections of different types of risks such as building and contents, cyber risks, liability, and so forth. Another perspective, particularly relevant for insurance companies and insurance pools, views a portfolio as consisting of several entities being insured, whether they are different insureds, policyholders, or fund members. Combining these two perspectives, each entity may have several risk types. For example, we have already seen the Wisconsin Property Fund, essentially an insurance pool, where we have data on \(N = 1,098\) fund members each of which may have up to \(p=6\) different risk types.
Using a latent variable approach, we are able to quantify the impact of contagion across pool members. Motivated by the Wisconsin Property Fund, consider a pool with \(N\) entities having \(p\) risks, and suppose the ith entity has \(p_i \le p\) of these risks. Our main interest is in the effects of dependency, so assume we understand the marginal distributions of each risk. As before, we can apply these marginal distributions to the risks to get the corresponding uniform outcomes and apply the inverse normal distribution so that \({\bf y}_i^*\) represents a \(p_i \times 1\) vector of risks that is normally distributed. Think of these transformed outcomes as being composed of two sources, \[ {\bf y}_i^* = {\bf D}_i^* \boldsymbol \alpha + \boldsymbol \epsilon_i, \] where \(\boldsymbol \alpha\) is a random vector that is common to all entities and \(\boldsymbol \epsilon_i\) is specific to the \(i\)th entity. Here, \({\bf D}_i^*\) is a known (nonstochastic) \(p_i \times p\) matrix of zeros and ones that indicate which risks the \(i\)th entity faces. Assuming that \(\boldsymbol \alpha\) and \(\boldsymbol \epsilon_i\) are independent, we can write \[ \begin{array}{ll} \mathrm{Var}({\bf y}_i^*) &= {\bf D}_i^* ~\mathrm{Var}(\boldsymbol \alpha) ~{\bf D}_i^{*'}+ \mathrm{Var}(\boldsymbol \epsilon_i) \\ &= {\bf D}_i^* {\bf A} {\bf D}_i^{*'}+ \boldsymbol \Omega_i^* = \boldsymbol \Sigma_i^* ,\\ \end{array} \] where \({\bf A}=\mathrm{Var}(\boldsymbol \alpha)\) and \(\mathrm{Var}(\boldsymbol \epsilon_i)=\boldsymbol \Omega_i^*\). To convert \({\bf y}_i^*\) to a vector of uniformly distributed variables, we rescale the variance to be one. To this end, define \({\bf y}_i = [diag(\boldsymbol \Sigma_i^*)]^{-1/2} ~{\bf y}_i^*\). Thus, we can compute dependent uniform random variates as \(V_{ij} = \Phi(y_{ij})\), \(j = 1, \ldots, p_i\). With this, we create realizations of dependent multivariate losses using \(X_{ij} = F_j^{-1}(V_{ij})\), \(j= 1, \ldots, p_i\) and \(i=1, \ldots, N\).
From this procedure, we see that dependency among entities is controlled by \({\bf A}=\mathrm{Var}(\boldsymbol \alpha)\). If \({\bf A}\) is a zero matrix, then there is no dependency among entities. Conversely, as it grows large (in some sense), it can dwarf the effect of the dependencies within a risk, effectively driving each \(\Omega_i^*\) to a matrix of zeros. That is, when \({\bf A}\) is “large,” then dependencies among entities dominates and one can effectively ignore dependencies among risk types.
Example 12.7. Effects of Contagion Among Pool Members. This is a continuation of Examples 12.2 and 12.4. The dependency among risk types, denoted by \(\boldsymbol \Omega_i^*\), has been given in Table 12.1. For dependency among pool members, we take \(\boldsymbol \alpha\) to be a vector of independent normal random variables with mean zero and standard deviation \(\sigma_{\alpha}\) so that \({\bf A}= \sigma_{\alpha}^2 ~{\bf I}\). This example uses \(R=2,000\) simulations, as with prior examples.
Table 12.12 summarizes six simulated distributions of the predicted pool claims that vary only by \(\sigma_{\alpha}\). The benchmark distribution uses \(\sigma_{\alpha}=0\) that corresponds to independence among pool members. Table 12.12 shows that \(VaR = 29.30\) for \(\alpha = 0.98\), as in Example 12.2. The table shows that each uncertainty measure increases with \(\sigma_{\alpha}\). In contrast, the table also shows that the mean of forecast claims is relatively constant over different levels of \(\sigma_{\alpha}\). This is by design; to isolate the effects of contagion, the latent variables are introduced in a way that affects only the uncertainty of the distribution, not the mean.
Figure 12.2 gives further detail of the six simulated distributions using density plots. The benchmark distribution corresponding to \(\sigma_{\alpha}=0\), the case of independence among pool members, is the most peaked and has the thinnest tails. As one increases the value of \(\sigma_{\alpha}\), the distribution becomes flatter and longer-tailed. We observed earlier in Example 12.2 that the normal distribution provided a sensible approximation to the simulated distribution when \(\sigma_{\alpha}=0\). Figure 12.2 demonstrates that this is no longer the case for large values of \(\sigma_{\alpha}\).
Show Example 12.7 R Code
|
Latent Variable Standard Deviation (\(\sigma_{\alpha}\))
|
||||||
|---|---|---|---|---|---|---|
| 0 | 0.05 | 0.10 | 0.25 | 0.50 | 0.75 | |
| Mean | 23.58 | 23.59 | 23.59 | 23.61 | 23.62 | 23.61 |
| \(VaR\) - 0.80 | 25.66 | 25.91 | 26.78 | 29.68 | 33.25 | 34.84 |
| Expected Shortfall - 0.80 | 27.42 | 27.93 | 29.34 | 35.68 | 47.07 | 56.71 |
| \(VaR\) - 0.98 | 29.30 | 30.28 | 32.44 | 42.24 | 63.74 | 83.78 |
| Expected Shortfall - 0.98 | 30.79 | 31.43 | 34.22 | 47.97 | 77.42 | 107.83 |
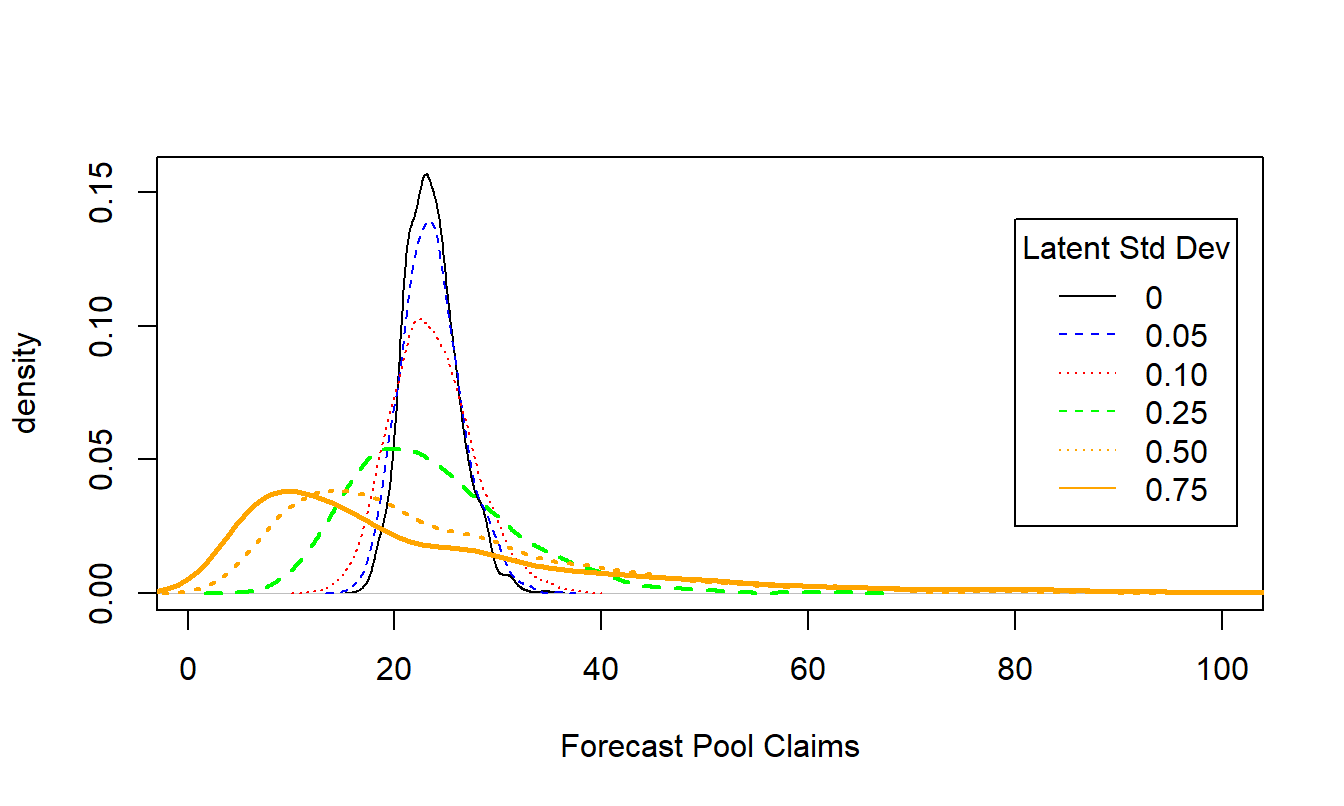
Figure 12.2: Density Plots of Simulated Portfolio Distribution by Latent Variable Standard Deviation
The structure underpinning Example 12.7 can be readily extended to encompass more realistic scenarios. For instance, the specification \({\bf A}= \sigma_{\alpha}^2 ~{\bf I}\) implies that dependencies among entities are the same for each risk. However, one may wish to allow for these dependencies to vary by risk type so that \({\bf A}\) is still diagonal but with different values of \(\mathrm{Var}(\alpha_j)\). Furthermore, for an application such as the Wisconsin Property Fund, one may wish to allow dependencies among entities of the same type such as schools or counties. The motivation is that outcomes are subject to common (latent) administrative regulations that restrict claim amounts. In addition, it is natural to introduce latent variables to account for spatial proximity due to common events such as weather occurrences (e.g. hail) that affect entities that are close to one another.
12.4.3 Pool Sensitivity to Contagion
One can get further insights into contagion among pool entities by applying the general structure developed for portfolio expectation dependence sensitivities in Section 12.2.3 to pools. Let us begin by rescaling the latent variable structure from the prior section using \([diag(\boldsymbol \Sigma_i^*)]^{-1/2}\) and defining:
- \({\bf D}_i = [diag(\boldsymbol \Sigma_i^*)]^{-1/2} ~{\bf D}_i^*\),
- \({\bf y}_i = [diag(\boldsymbol \Sigma_i^*)]^{-1/2} ~{\bf y}_i^*\),
- \(\boldsymbol \Omega_i = [diag(\boldsymbol \Sigma_i^*)]^{-1/2} ~\boldsymbol \Omega_i^* [diag(\boldsymbol \Sigma_i^*)]^{-1/2}\), and
- \(\boldsymbol \Sigma_i = [diag(\boldsymbol \Sigma_i^*)]^{-1/2} ~\boldsymbol \Sigma_i^* [diag(\boldsymbol \Sigma_i^*)]^{-1/2}\).
With this rescaling and equation (12.2), the weights for the pool sensitivity to contagion may be expressed as \[ \begin{array}{ll} W_{\sigma}(\mathbf{X}) &= \left[ \mathbf{ns}(\mathbf{X})^{\prime} \boldsymbol \Sigma^{-1} {\bf D} \right] (\partial_{\sigma} {\bf A}) \left[ {\bf D}' \boldsymbol \Sigma^{-1} \mathbf{ns}(\mathbf{X}) \right] ,\\ \end{array} \] with the notation \({\bf D} = ({\bf D}_1', {\bf D}_2', \dots, {\bf D}_N')'\) and \(\boldsymbol \Omega = blkdiag(\boldsymbol \Omega_1, \boldsymbol \Omega_2, \ldots, \boldsymbol \Omega_N)\). The weights can be computed using \[ \begin{array}{ll} \mathbf{ns}(\mathbf{X})^{\prime}\boldsymbol \Sigma^{-1} {\bf D} &= \left\{\sum_{i=1}^N\mathbf{ns}(\mathbf{X})^{\prime}_i \boldsymbol \Omega^{-1}_i {\bf D}_i \right\} \left\{ {\bf I} - \left[{\bf I} + {\bf A}{\bf D}' \boldsymbol \Omega^{-1} {\bf D} \right]^{-1} {\bf A}{\bf D}' \boldsymbol \Omega^{-1} {\bf D}\right\} \end{array} \] and \({\bf D}' \boldsymbol \Omega^{-1} {\bf D}\) \(= \sum_{i=1}^N {\bf D}_i' \boldsymbol \Omega_i^{-1} {\bf D}_i\). Although complex in appearance, these expressions are at most dimensions \(p \times p\) and thus easy to calculate even when the number of entities \(N\) is in the thousands or more.
\(Under~the~Hood.\) Development of Pool Contagion Weights
With these weights, one can calculate general portfolio expectation dependence sensitivities as in equation (12.1) and use these to compute pool dependence sensitivities for risk measures value-at-risk and expected shortfall, similar to Section 12.3.2. This is illustrated in the following example.
Example 12.8. Expected Shortfall Sensitivities for Contagion in an Insurance Pool. This is a continuation of Examples 12.4 and 12.7. This example uses \({\bf A} = {\bf 0}\) so that we can utilize simulated values and make meaningful comparisons with prior examples. In addition, the weights are relatively easy to compute because the weighted sum of normal scores reduces to \(\mathbf{ns}(\mathbf{X})^{\prime}\boldsymbol \Sigma^{-1} {\bf D}\) \(= \sum_{i=1}^N \mathbf{ns}(\mathbf{X})^{\prime}_i ~\boldsymbol \Omega^{-1}_i {\bf D}_i\). In addition, when \({\bf A} = {\bf 0}\), all diagonal elements of \({\boldsymbol \Sigma}_i^*\) are one meaning that no rescaling is required.
R Code for Example 12.8
| Risk | \(ES\) Sensitivity | Risk | \(ES\) Sensitivity |
|---|---|---|---|
| BC | 268.219 | PO | -76.709 |
| IM | 6.494 | CN | -0.002 |
| PN | -1.394 | CO | 127.098 |
| All Risks | 323.705 |
With these weights, one may compute the expected shortfall sensitivities using the result in Example 12.5. Illustrative calculations are in Table 12.13. For this table, the confidence level is \(\alpha = 0.80\) and the expected shortfall is expressed in millions of dollars. The sensitivity corresponding to BC means that a single latent variable, common to all entities, with dispersion parameter \(\sigma_{1,\alpha}^2\) was used for the first risk. As this dispersion parameter increases by one unit, the table indicates one can anticipate \(ES_{0.80}\) to increase by 268.219. Similar interpretations hold for the other risks.
For the All Risks category, now there is a single latent vector, common to all entities, with common dispersion parameter \(\sigma_{\alpha}^2\). This is the structure from the earlier Example 12.7. For interpretation, as this dispersion parameter increases by \(0.05^2\) units, the table indicates one can anticipate \(ES_{0.80}\) to increase by \(0.05^2 \times\) 323.705, which is 0.81. This is comparable to Table 12.12, where we see the increase is \(27.93 - 27.42 = 0.51\).
12.4.4 Insurance Companies as Risk Pools
Conceptually, an insurance company writes a contract in which it agrees to take on the uncertain risk of a consumer in exchange for a certain price. An insurance company is essentially a collection of such contracts. An insurer exists to spread the risks of many policyholders; insurance systems that can include many insurers are predicated on the pooling of contracts.
Insurers pool risks to enjoy the benefits of diversification. However, these benefits depend on the dependence among risks. Some risks are negatively associated and so provide a natural hedge for one another, offering diversification benefits. For example, consider the mortality risk in life insurance and annuities. If a policyholder lives longer than anticipated, benefit payments in life insurance are further in the future and thus lower in terms of the present value of today’s money. Conversely, for a life annuity, the insurer pays while the policyholder is alive meaning a longer lifespan results in more payments. In sum, insurers pay less in life insurance but more in annuities, demonstrating a natural negative association.
In contrast, insurance risks are more commonly positively associated, such as the risk of flood to homes located close to one another. There may be few diversification benefits to pooling such positively associated risks.
The Chapter 6 risk controls represent actionable strategies that insurers can use to establish the composition of a pool. Selection of risks can be based on coverages, perils, or policyholders, or indirectly through ratemaking. Reinsurance treaties influence the insurer’s retained risk, helping to determine the pool composition. This raises the question of how an insurer can measure the benefits achieved through a risk control strategy. And this is precisely why an insurer may wish to utilize the tools introduced in this book.
12.5 Summary and Concluding Remarks
At a fundamental level, dependence is a key concept underpinning risk sharing. This chapter provides approaches for quantifying the impact of dependence on risk sharing, and risk transfer, arrangements. These approaches are applied at both global and local levels, for collections of risks that are smaller (portfolios) and larger (pools). The portfolio expectation dependence sensitivity is highlighted as a useful tool for assessing local dependencies.
For managing pools, Section 12.4.1 emphasizes the importance of field-specific models of dependencies that offer insights into the effects and propagation of dependencies within a system. Additionally, the simulation models of contagion presented in this chapter can serve as a useful starting point for analyzing the effects of dependencies in large pools.
To emphasize the relevance of the tools and approaches advocated here, it is useful to acknowledge their limitations, as follows.
Absence of Dynamic Dependencies. One of main limitations of this chapter (and indeed, the entire book) has been the lack of development to address relationships over time, known as dynamic or temporal dependencies. This is significant because many dependencies occur over time and many insurance contracts are long-term, meaning they are in effect for more than one financial period. Indeed, the entire life insurance industry is based on long-term contracts. It is also a limitation from an academic perspective in that there is a host of dynamic models developed for the sister financial investments portfolio problems; presumably, these models could be leveraged to provide reasonable starting points for the insurable risks portfolios considered.
Despite these motivating factors, the approach of this chapter and book has been to emphasize one-period (sometimes known as cross-sectional) models of dependence. The goal has been to provide a careful analysis in a manner accessible to a broad audience, allowing for risks whose distributions have a mixture of discrete and continuous components, risks that are long-tail, risk retention rules that are nonlinear, and complex multivariate collections of retained risks. The aim is to provide a practically useful approach that also serves as a springboard for future investigations that may accommodate dynamic relationships.
On the Use of Elliptical Copulas. Another potential limitation is the emphasis on elliptical copulas for modeling dependencies. For example, Section 12.2.2 demonstrated how to compute sensitivity dependencies by considering elliptical copula dependence models such as the Gaussian copula. (Mathematically, this was achieved by essentially changing the basis of the distribution.) Some may find this notion of dependence to be restrictive. However, especially when combined with longitudinal and panel data models that incorporate mean effects and trends, we find that such copula models account for many situations of interest in actuarial and risk management applications, cf. Frees, Lee, and Yang (2016).
Note, however, for many applications, that the limitations of elliptical copulas have been well documented, cf. Frahm, Junker, and Szimayer (2003). Naturally, there are many non-elliptical copulas and other models of dependence, such as latent effects models, and this work may provide a platform for additional investigations.
12.6 Supplemental Materials
12.6.1 Further Resources and Reading
Naturally, effects of contagion have long been known to insurance researchers. As one example, an investigation of contagion due to a common interest environment for life and annuity risks was provided in earlier work by the author, Frees (1990).
For managing pools, some insights from the literature on optimal insurance are developed in the paper Bernard, Liu, and Vanduffel (2020) that refers to pools as the case of “multiple policyholders.”
Mathematically, the topic of capital allocation is closely related to the optimal risk retention problem. In insurance, an important practical problem is to allocate a firm’s total pool of capital to individual business units. As emphasized in Dhaene et al. (2012), many of the principles for doing so can be expressed as a constrained optimization problem. There is a substantial actuarial literature on this problem; see, for example, Guo, Bauer, and Zanjani (2021) for a recent review. Despite the parallels, this book does not take up this problem because the focus here has been on developing optimal retention policies for general risk-owning firms that may not include insurers. However, it is hoped that future researchers will be able to exploit potential synergies between these different problems.
This chapter (and book) has loosely described diversification benefits without providing formal definitions. As noted in Mainik and Embrechts (2013), a “mathematical basis of portfolio diversification was given by Markowitz (1952) for multivariate Gaussian models” but does not work well for risks typically faced in insurance modeling. As one step, their work proceeds to provide more formal definitions for representations known as “multivariate regular variation” models. The literature continues to develop. For example, see the recent work of Han, Lin, and Wang (2023) that are directed to the risk measures \(VaR\) and \(ES\) utilized here. It is hoped that the work in this book provides an application area that future researchers will be able to use to motivate an agreed-upon formal definition of “diversification” for managing insurable risks.
12.6.2 Exercises
Section 12.2 Exercises
Exercise 12.1. Reinsurance Expected Payments. Under the assumption of independence, determine simulation - based reinsurance expected payments by upper limits retention per limit. Your results should reproduce Table 12.14; these findings are consistent with Table 12.3 that was produced under a model that allows for dependence.
Show Exercise 12.1 Solution
|
Limit (\(u\))
|
Retention per Limit (\(d/u\))
|
||||
|---|---|---|---|---|---|
| 0.0 | 0.25 | 0.50 | 0.75 | 0.95 | |
| 10,000 | 19077 | 11561 | 6915 | 3192 | 606 |
| 100,000 | 37821 | 14420 | 7341 | 3059 | 546 |
| 500,000 | 52674 | 13139 | 6367 | 2594 | 458 |
| 1,000,000 | 58484 | 12214 | 5884 | 2385 | 419 |
Exercise 12.2. Two Risk Portfolio. As seen in Chapter 5, when there are only \(p=2\) risks, distributions can be evaluated using double integration that can be readily computed without resorting to simulation techniques. It is helpful to go through this approach for two reasons. First, it provides some independent corroboration of the simulation based techniques. Second, one can quickly see the complexity of this approach and how this increases as the dimension \(p\) increases. Integration-based calculations certainly have their place, they can be quicker and are more accurate than simulation-based methods. However, they are limited in that they do not readily scale up to problems of interesting complexity.
a. Portfolio Distribution. When \(p=2\), let \(\rho = \sigma\) be the dependence parameter of interest. The portfolio (\(S=X_1+X_2\)) distribution function is \[ \begin{array}{lc} F(x;\rho) = \Pr(X_1 + X_2 \le x) = \int^x_0 C_2[F_1(x- z),F_2(z)] ~f_2(z)~d z ,\\ \end{array} \] where recall the partial derivative of the copula \(C_2(v,w) = \partial_w C(v,w)\) (see Appendix Chapter 14).
Show that one can express the differentials as
\[
\begin{array}{ll}
F_x(x;\rho) =\partial_x F(x;\rho)
= \int^{x}_0 c[F_1(x- z),F_2(z)] f_1(x- z) f_2(z)d z \\
\end{array}
\]
and
\[
\begin{array}{ll}
F_{\rho}(x;\rho) = \partial_{\rho} F(x;\rho) = \int^x_0 \partial_{\rho} ~C_2[F_1(x- z),F_2(z)] f_2(z) d z .
\end{array}
\]
Fortunately, functions such as \(\partial_{\rho} ~C_2(\cdot)\) are available in R package VineCopula.
b. Special Case. Gaussian Copula. To see how this works in a special case, consider uniform marginals and the Gaussian (normal) copula with partial/conditional distribution function. Derive computable versions of the results in part (a).
Solution to Exercise 12.2
Exercise 12.3. Portfolio Distribution with Gamma and Pareto Risks. Returning to a familiar set up introduced in Example 4.6, assume:
- That \(X_1\) has a gamma distribution with mean 10,000 and scale 5,000. With these parameters, the 95th percentile of \(X_1\) is 23,719.
- That \(X_2\) has a Pareto distribution with mean 1000 and scale 2,000. With these parameters, the 95th percentile of \(X_2\) is 3,429.
- The dependence between risks \(X_1, X_2\) is based on a Gaussian copula.
Using numerical integration, produce code that yields results comparable to Tables 12.15 and 12.16 for confidence levels \(\alpha\) 0.95 and 0.90, respectively.
R Code for Exercise 12.3 Dependence Sensitivity
| Quantile | Density | Deriv:Rho Sum | Dependence Sensitivity (in percentages) | |
|---|---|---|---|---|
| Rho= -0.9 | 23843 | 0.00000930 | -0.0031 | 3.38 |
| Rho= -0.3 | 24434 | 0.00000835 | -0.0142 | 16.99 |
| Rho= 0 | 25005 | 0.00000812 | -0.0168 | 20.71 |
| Rho= 0.3 | 25645 | 0.00000767 | -0.0167 | 21.74 |
| Rho= 0.9 | 26940 | 0.00000655 | -0.0137 | 20.99 |
| Quantile | Density | Deriv:Rho Sum | Dependence Sensitivity (in percentages) | |
|---|---|---|---|---|
| Rho= -0.9 | 19617 | 0.00001585 | -0.0083 | 5.24 |
| Rho= -0.3 | 20235 | 0.00001620 | -0.0231 | 14.23 |
| Rho= 0 | 20664 | 0.00001566 | -0.0218 | 13.91 |
| Rho= 0.3 | 21062 | 0.00001488 | -0.0184 | 12.39 |
| Rho= 0.9 | 21681 | 0.00001321 | -0.0107 | 8.08 |
What do we learn from this exercise? Comparing the results of Tables 12.15 and 12.16 are interesting.
- In terms of value at risk, moving the level of confidence from 0.95 to 0.90 is more important than the dependence, except perhaps at the extremes.
- When \(\alpha = 0.90\), we see that the dependence sensitivity becomes smaller for large values of \(\rho\).
Exercise 12.4. Portfolio Distribution - Simulation Based Computations. The results from Exercise 12.3 are based on numerical integration. This exercise investigates whether one can replicate these findings using a simulation approach. Specifically, consider five million simulated replicates using level of confidence \(\alpha =\) 0.95.
For this exercise, produce code that yields results comparable to Table 12.17. Note that the results from this table are largely consistent with those from Table 12.15. This suggests that we can be comfortable when calculating dependence sensitivities using simulation.
R Code For Exercise 12.4
| Quantile | Density | Deriv:Rho Sum | Dependence Sensitivity (in percentages) | |
|---|---|---|---|---|
| Rho= -0.9 | 23858 | 0.00000828 | -0.0016 | 1.96 |
| Rho= -0.3 | 24461 | 0.00000833 | -0.0136 | 16.32 |
| Rho= 0 | 24992 | 0.00000817 | -0.0168 | 20.53 |
| Rho= 0.3 | 25643 | 0.00000765 | -0.0167 | 21.83 |
| Rho= 0.9 | 26949 | 0.00000661 | -0.0117 | 17.69 |
Section 12.3 Exercises
Exercise 12.5. Simulation. To supplement the portfolio expectation dependence sensitivity, this exercise develops an approach to computing \(\partial_{\sigma}~h({\bf X}_r)\). This is a partial derivative with respect to a single simulated value of a function of risks \(h({\bf X})\).
For simplicity, assume that dependence among risks are captured by a Gaussian copula with dependence matrix \(\boldsymbol \Sigma\). Further define \(f_j\) and \(F_j\) to be the density and distribution function of the \(j\)th marginal distribution and \(h_j(x_1, \ldots, x_p) = \partial_{x_j} h(x_1, \ldots, x_p)\).
Starting with a vector of independent standard normal random vectors, \({\bf N}^{ind}\), show that one could compute the partial derivative using the following terms:
- \(V_j = \Phi({\bf 1}_j' \boldsymbol \Sigma ^{1/2}{\bf N}^{ind})\),
- \(\partial_{\sigma} X_j = \frac{1}{f_j[F_j^{-1}(V_j)]}~ \phi\left({\bf 1}_j' \boldsymbol \Sigma ^{1/2}{\bf N}^{ind}\right) ~{\bf 1}_j' ~(\partial_{\sigma} \boldsymbol \Sigma ^{1/2})~{\bf N}^{ind}\), and
- \(\partial_a~h(X_1, \ldots, X_p) = \sum_{j=1}^p~h_j[X_1, \ldots, X_p] \left( \partial_a X_j\right)\).
Note here that \(\partial_{\sigma} \boldsymbol \Sigma ^{1/2}\) can be determined via numerical differentiation.
Solution to Exercise 12.5
Exercise 12.6. Simulation with Elliptical Copulas. Extend the work of Exercise 12.5 to include general elliptical copulas, beginning with \(t\)-copulas. Hint: Refer to Hofert et al. (2018) for discussions of simulating outcomes with elliptical copulas. In particular, see their Algorithm 3.1.8 for an approach for simulating \(t\)-copulas.