2 data example;
3 set sashelp.class;
4 bmi = (weight/height**2)*703;
5 run;
NOTE: There were 19 observations read from the data set SASHELP.CLASS.
NOTE: The data set WORK.EXAMPLE has 19 observations and 6 variables.
An Introduction to SAS Data Steps
SAS is a “procedural” style of programming language, like Stata and SPSS, and in contrast to “functional” style languages like R, Python, and Julia. In SAS, most statistical analysis is carried out by specifying a procedure (a PROC step). In general, each statistical procedure makes one or more passes through a data set.
Preparing your data for analysis is the job of the DATA step. While other statistical programming languages enable “stream of consciousness” data manipulation, making it very easy to interleave data manipulations and analysis, SAS requires you to package your data manipulation into distinct blocks of code, giving SAS a more “structured programming” character.
At the same time, SAS DATA steps are carried out observation-by-observation rather than variable-by-variable. This means the sequence of data operations is different in SAS (disk-based data) versus Stata, R, and Python (memory-resident data).
Uses of DATA Steps
Typical uses of a DATA step include:
- creating new variables
- recoding existing variables
- importing text data
- copying data
- subsetting data (extracting observations or variables)
- appending data (adding observations)
- merging data (adding variables)
- reshaping data (long versus wide)
If your task manipulates individual data values or has instructions for each observation, it belongs in a DATA step.
Outline of a DATA Step
Every DATA step begins with the keyword DATA. A DATA step ends with one of:
- a
RUNstatement, or - the beginning of a new DATA or PROC step, or
- then end of the program file (in batch mode).
(This is also how SAS recognizes the end of any PROC step.) In these pages we will use RUN statements. These provide visual punctuation in your code, and also make it easier to run select blocks of code when using an interactive SAS environment.
In between DATA and RUN we write statements that detail our data manipulation.
data outputdataset;
--- data manipulation statements ---
run;The DATA Statement
The DATA statement itself names an output data set. Almost every DATA step creates or replaces an entire data set. A typical DATA step names an output data set and reads and creates data
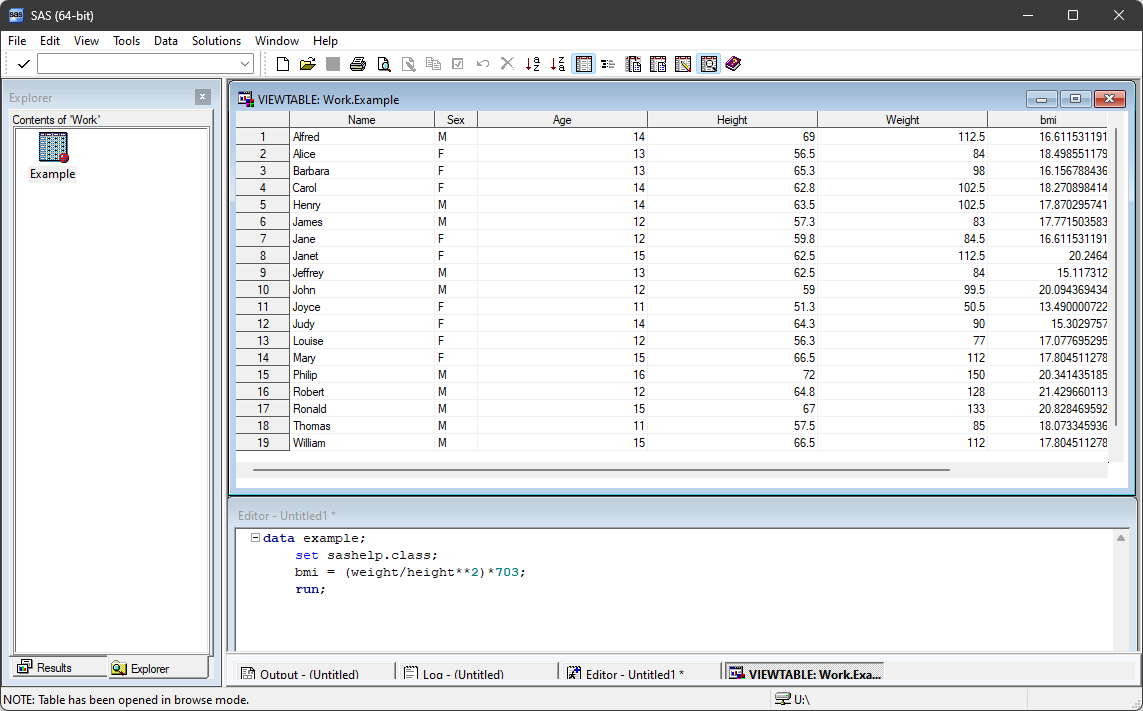
For example if we run the code
data example;
set sashelp.class;
bmi = (weight/height**2)*703;
run;This creates a new data set, example, by reading observations from an existing SAS data set, class, and creating a new variable, bmi, based on the height and weight data in the class data. The log assures us this code ran, producing a data set with 19 observations and 6 variables.
Note that it is possible to replace a data set by specifying both the input and output data sets with the same name. Be sure you can recreate your data set before you do this with a permanent data set!
More about Output Data Sets
Less commonly, you might want to read and manipulate individual data values without saving a data set. Or you might want to create multiple output data sets from the same input. It is also worth noting that there is an default output data set name!
No Output Data
To avoid creating a new data set, specify
data _null_;For example, to identify underweight teens in this (simulated) data, and write their information to the log (or a file)
2 data _null_;
3 set sashelp.class;
4 where (weight/height**2)*703 lt 16;
5 put name sex age;
6 run;
Jeffrey M 13
Joyce F 11
Judy F 14
NOTE: There were 3 observations read from the data set SASHELP.CLASS.
WHERE ((weight/(height**2))*703)<16;
What this does not do is create a new data set (or a new variable). This can be especially useful when you are trying to examine outliers in your data.
Multiple Output Data Sets
This is especially useful when you want to create multiple subsets of a large data set. It is efficient because it requires only one pass through the data. Specify
data output1 output2 ...;and use OUTPUT statements to direct observations to the appropriate subset(s).
2 data girls boys;
3 set sashelp.class;
4 if sex eq "F" then output girls;
5 else if sex eq "M" then output boys;
6 run;
NOTE: There were 19 observations read from the data set SASHELP.CLASS.
NOTE: The data set WORK.GIRLS has 9 observations and 5 variables.
NOTE: The data set WORK.BOYS has 10 observations and 5 variables.
In the typical DATA step, there is an implied OUTPUT statement at the bottom of the step. Here, we make the OUTPUT explicit, conditional, and name where each observation’s output should be directed. More about OUTPUT statements.
Default Data Set Name
Seldom useful, but this illustrates how SAS has numerous defaults. Sometimes defaults are useful, sometimes they can trip you up! Good style is to always explicitly name your data sets.
The default output data set name is datan, where “n” depends on what other data sets named “data” you already have. Specify a bare DATA statement
data ;For example
2 data ;
3 set sashelp.class;
4 run;
NOTE: There were 19 observations read from the data set SASHELP.CLASS.
NOTE: The data set WORK.DATA1 has 19 observations and 5 variables.
Here we see that SAS has copied the data to a new data set, DATA1, located in the WORK library.
Some Simple Data Steps
Copying a Data Set
To copy a data set using a DATA step, simply name a new output data set, and SET (read) the original data set, observation by observation. The basic form is just:
data new;
set original;
run;For example:
2 data class;
3 set sashelp.class;
4 run;
NOTE: There were 19 observations read from the data set SASHELP.CLASS.
NOTE: The data set WORK.CLASS has 19 observations and 5 variables.
Here we have kept the same data set name, but copied the data from the SASHELP library to the WORK library.
Note that PROC COPY and PROC DATASETS also provide efficient methods of copying data sets.
Creating a New Variable
A DATA step that reads data and creates new variables is probably the most common task.
New variables are given values with assignment statements.
variable = expression;2 data new;
3 set sashelp.class;
4 bmi = (weight/height**2)*703;
5 run;
NOTE: There were 19 observations read from the data set SASHELP.CLASS.
NOTE: The data set WORK.NEW has 19 observations and 6 variables.
Here we create a new variable, bmi.
Note that it is possible to overwrite an existing variable with an assignment statement. Be sure you can recreate your data if you do this!
Importing Text Data
Text data is usually imported from a file. In the SAS documentation, DATALINES are often used in place of a file.
The basic form is:
data new;
infile "file-name";
input variable-list;
run;The two key statements are INFILE, naming where the text data are read from, and INPUT, naming the variables to read. Where there are DATALINES, these follow immediately after the DATA step (before any RUN statement!). For example:
data new;
infile datalines;
input x y;
datalines;
1 2
3 4
5 6
;Subsetting Data
We take subsets of observations with WHERE or IF statements. We take subsets of variables with DROP or KEEP statements.
data new;
set sashelp.class;
where sex = "F"; /* subset observations */
keep name sex age; /* subset variables */
run;
proc print; run; Obs Name Sex Age
1 Alice F 13
2 Barbara F 13
3 Carol F 14
4 Jane F 12
5 Janet F 15
6 Joyce F 11
7 Judy F 14
8 Louise F 12
9 Mary F 15Appending Data
We append (concatenate) data sets by naming multiple input data sets on a single SET statement. The form is
data new;
set original-1 original-2 ...;
run;Note PROC APPEND is an efficient method of appending data sets as well.